













強化學習Scaling Law錯了?無需蒸餾,數據量只要1/6,效果還更好
DeepSeek-R1帶火了使用強化學習訓練LLM。在訓練中,AI靈機一動,讓作者耳目一新,甚至因此驚嘆到:這就是強化學習的力與美!

DeepSeek-R1-Zero驚艷了研究人員
然而,對RL訓練的理解存在空白:這些工作的訓練數據的透明度有限,誰知道是方法好還是數據集質量好?
剛剛出爐的新論文揭示了RL訓練的另一面,探討了一個核心問題:
在提升語言模型推理能力方面,什么真正決定了強化學習(RL)訓練數據的有效性?
研究團隊對「擴大RL訓練數據規模,就能提升模型性能」這一觀念提出了挑戰。
核心發現是,訓練樣本的質量和相關性遠比數量重要。
通過廣泛的實證分析,新研究得出了一些令人驚訝的觀察結果,這些結果從根本上改變了對RL訓練動態的理解:
- 經過精心挑選的1389個RL訓練樣本子集,可以實現和8523個樣本的完整數據集相當甚至更優的性能。
- 新方法「學習影響測量」(LIM),可以有效地預測哪些樣本對模型改進的貢獻最大,消除了手動樣本管理的需要,而且易于擴展。
- 通往更好推理能力的道路,可能不在于簡單地擴大RL訓練數據規模,而在于更具選擇性地使用哪些樣本。

項目地址:https://github.com/GAIR-NLP/LIMR
Scaling Law適用于強化學習訓練嗎?
在這項工作中,在一個基本場景,探索RL訓練數據的Scaling Law:直接從沒有經過知識蒸餾的基礎模型開始(類似于Deepseek R1-zero的設置)。
對RL訓練數據需求的理解不足,面臨下列難題:
- 由于缺乏明確的數據規模基準,必須依賴反復試驗,導致資源利用效率低下,而結果也可能不是最優的。
- 樣本數量如何影響模型性能,該領域缺乏對該問題的系統分析,很難做出資源分配的明智決策。
更重要的是,這種不確定性提出了關鍵問題:
擴大RL訓練數據規模真的是提高模型性能的關鍵嗎?
或者是否忽略了更基本的因素,例如樣本質量和選擇標準?
學習影響測量
學習影響測量(Learning Impact Measurement,LIM),是一種系統的方法,用于量化和優化強化學習中訓練數據的價值。
新方法通過分析學習動態,識別最有效的訓練樣本,從而應對強化學習訓練中數據效率的關鍵挑戰。
RL訓練中的學習動態
為了理解訓練數據和模型改進之間的關系,使用MATH-FULL數據集進行了廣泛的分析,數據集包含8,523個難度級別不同的數學問題。
初步研究表明,不同的訓練樣本對模型學習的貢獻是不平等的,這與將所有樣本統一對待的傳統方法相反。
如圖2a所示,觀察到不同的學習軌跡:一些樣本表現出穩定的性能模式,而另一些樣本則顯示出復雜的學習動態,這些動態似乎驅動了顯著的模型改進。
圖a解題獎勵軌跡揭示了不同的模式:保持接近零獎勵的樣本、快速獲得高獎勵的樣本,以及顯示出具有不同改進率的動態學習進展的樣本。
圖b表明較高的LIM分數反映了與模型學習軌跡更好的對齊,其中顯示出相似增長模式的軌跡獲得更高的分數。

圖2:(a)MATH-FULL數據集中訓練樣本在不同epoch的學習動態分析。(b)樣本學習軌跡與平均獎勵曲線(紅色)的比較。
這些觀察結果引出了核心見解:檢查單個樣本與模型的整體學習進程的對齊程度,可以系統地衡量強化學習訓練中數據的價值。
這種理解構成了新方法LIM的基礎。
學習影響測量(LIM)
LIM的核心是模型對齊的軌跡分析。
它根據訓練樣本對模型學習的貢獻,來評估它們的價值。
新研究的主要發現是,學習模式與模型整體性能軌跡互補的樣本往往對優化更有價值。
學習影響測量(LIM)主要分為兩步:(1)分析模型對齊的軌跡;(2)計算一個歸一化對齊分數。
考慮到神經網絡學習通常遵循對數增長模式,使用模型的平均獎勵曲線,作為衡量樣本有效性的參考(圖2b):
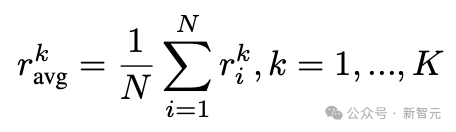
其中:r_k^i表示樣本i在epoch k的獎勵;N是樣本總數;K是總的epoch數。
對于每個樣本,LIM計算一個歸一化對齊分數:
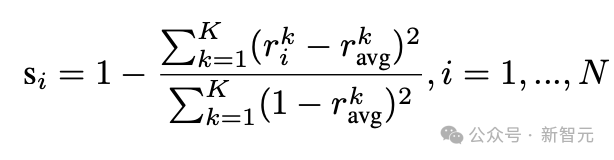
本質上,這個公式是在平均獎勵變化趨勢上,比較單個樣本與整體的相似程度。
如果一個樣本的獎勵變化趨勢與整體趨勢高度一致(即,當整體獎勵上升時,該樣本的獎勵也上升,反之亦然),那么它的對齊分數就會較高。
反之,如果一個樣本的獎勵變化趨勢與整體趨勢差異較大,那么它的對齊分數就會較低。
該分數量化了樣本的學習模式與模型整體學習軌跡的對齊程度,分數越高表示對齊程度越好。
尋找「黃金」樣本
基于對齊分數,LIM采用了選擇性抽樣策略:s_i>θ,其中θ作為質量閾值,可以根據具體要求進行調整。在實驗中,研究人員設置θ=0.6產生了優化的數據集 (LIMR),其中包含來自原始數據集的1,389個高價值樣本。
基線數據選擇方法
在開發核心方法時,研究人員探索了幾種替代方法,有助于最終方法的形成和驗證。
這些方法為強化學習中的數據選擇提供了寶貴的見解。
- 隨機抽樣基線(RAND):從MATH-FULL中隨機選擇1389個樣本,以匹配主要方法的大小,為評估選擇性抽樣的有效性提供了一個基本的參考點。
- 線性進展分析方法(LINEAR):根據在訓練周期中持續顯示穩步改進的一致性,來評估樣本。雖然這種方法捕獲了逐漸進展的樣本,但它經常錯過有快速早期收益然后趨于穩定的有價值的樣本。使用閾值θ=0.7,此方法產生1189個樣本。
獎勵設計
與Deepseek R1類似,使用基于規則的獎勵函數。
具體來說,對于正確答案,獎勵為1;對于不正確但格式正確的答案,獎勵為-0.5;對于格式錯誤的答案,獎勵為-1。形式上,這可以表示為:

實驗結果
為了驗證LIMR方法的有效性,研究團隊開展了一系列實驗。
在實驗設置上,訓練環節采用OpenRLHF框架中實現的近端策略優化(PPO)算法,以Qwen2.5-Math-7B為初始策略模型。
評估環節選擇了多個具有挑戰性的基準測試,包括MATH500、AIME2024和AMC2023。為提高評估效率,借助vLLM框架進行評估。
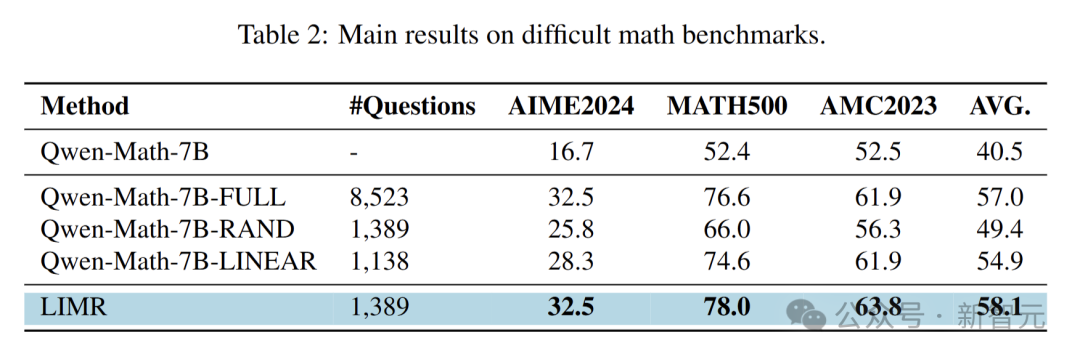
從不同數據選擇策略的對比來看,直接在Qwen-Math-7B上使用MATH-FULL數據集進行強化學習訓練,模型性能有顯著提升。
使用MATH-RAND數據集訓練,與完整數據集相比,平均準確率下降8.1%;MATH-LINEAR的準確率損失為2%。
而LIMR盡管數據集規模減少了80%,但性能與MATH-FULL幾乎相當。這充分證明在強化學習中,真正起關鍵作用的往往只是一小部分問題。

進一步分析訓練過程中的各項指標演變,發現LIMR和MATH-FULL的準確率曲線近乎一致,且均明顯優于MATH-RAND。
在序列長度方面,MATH-FULL的訓練曲線不穩定,而LIMR的曲線先下降后逐漸上升。訓練獎勵方面,LIMR的獎勵曲線上升更快,最終接近1.0,這表明模型在訓練過程中能夠更有效地利用LIMR數據集進行學習。
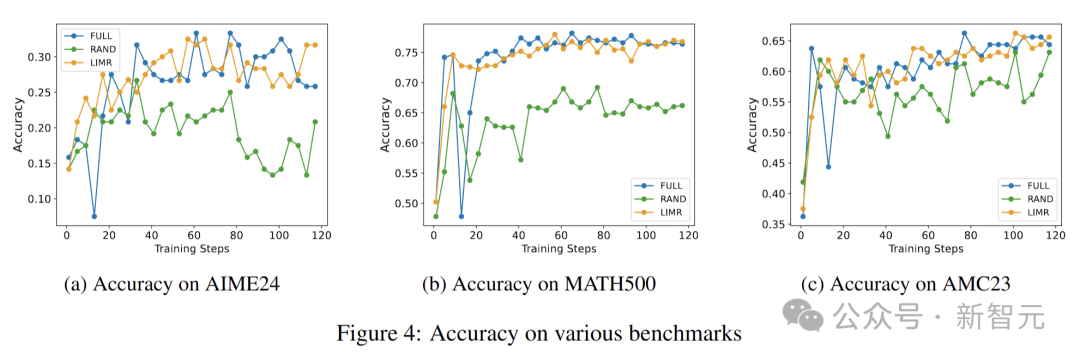
圖4展示了在三個具有挑戰性的基準測試上模型性能的對比分析。結果表明,LIMR在所有三個基準測試上的性能都與MATH-FULL相當,同時顯著優于MATH-RAND。
值得注意的是,LIMR在AIME24和AMC23數據集上表現出色,有力證明了其性能提升并非歸因于對單個數據集的過擬合,而是反映了模型數學推理能力的真正提高。
RL的數據效率優于SFT
研究者發現,對于數據稀疏且模型較小的情況,強化學習>監督微調!
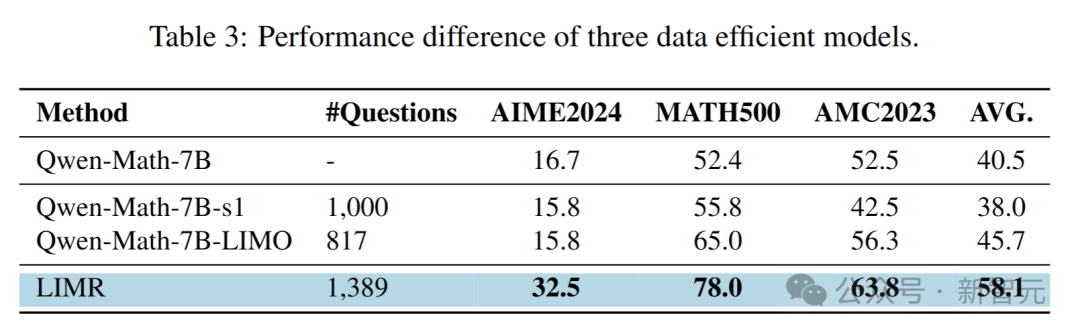
研究者用來自s1的1000條數據和來自LIMO的817條數據,通過監督微調對Qwen-2.5-Math-7B進行訓練,并與LIMR進行比較。
實驗結果表明,在相同的約1000個問題下,與LIMO和s1相比,LIMR在AIME上的相對提升超過100%,在AMC23和MATH500上的準確率提高了10%以上。
這進一步強調了選擇適合模型的數據,而不是盲目選擇更具挑戰性的數據的重要性。在數據稀疏的場景以及小模型應用中,強化學習結合有效的數據選擇策略,能有效地提升模型的推理能力。
本文的方法不僅為研究人員提供了一種高效、可擴展的RL訓練解決方案,還揭示了提升推理能力的關鍵可能在于優化數據質量,而非單純增加數據量。
與監督微調(SFT)的對比實驗表明,當RL結合高效的數據選擇策略時,在數據有限的小模型上表現尤為突出。






























