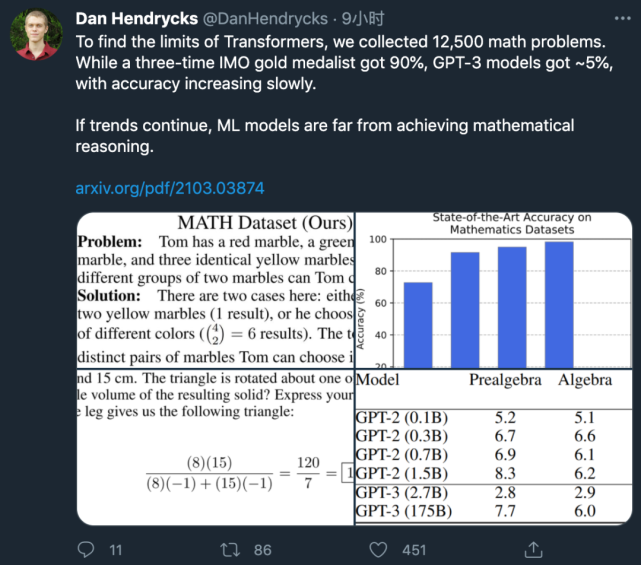
奧賽冠軍都做不對的題,卻被拿來考ML模型?GPT-3:我不行
為了衡量機器學習模型的數(shù)學求解能力,來自 UC 伯克利和芝加哥大學的研究者提出了一個包含 12, 500 道數(shù)學競賽難題的新型數(shù)據(jù)集 MATH,以及幫助模型學習數(shù)學基礎知識的預訓練數(shù)據(jù)集 AMPS。研究發(fā)現(xiàn),即使是大參數(shù)的 Transformer 模型準確率也很低。
許多學術研究探討數(shù)學問題求解,但對于計算機而言這超出了其能力范疇。那么機器學習模型是否具備數(shù)學問題求解能力呢?
來自加州大學伯克利分校和芝加哥大學的研究者為此創(chuàng)建了一個新型數(shù)據(jù)集 MATH。該數(shù)據(jù)集包含 12, 500 道數(shù)學競賽難題,每個數(shù)學題都有完整的逐步求解過程,可用來教機器學習模型生成答案和解釋。為了促進未來研究,提升模型在 MATH 數(shù)據(jù)集上的準確率,研究者還創(chuàng)建了另一個大型輔助預訓練數(shù)據(jù)集,它可以教模型數(shù)學基礎知識。
盡管通過這些方法提升了模型在 MATH 數(shù)據(jù)集上的準確率,但實驗結果表明,準確率仍然很低,即使 Transformer 模型也不例外。研究者還發(fā)現(xiàn),僅靠增加預算和模型參數(shù)量并不能實現(xiàn)強大的數(shù)學推理能力。擴展 Transformer 能夠自動解決大多數(shù)文本任務,但目前仍無法解決 MATH 問題。
該研究第一作者 Dan Hendrycks 發(fā)推表示:
國際數(shù)學奧林匹克競賽(IMO)三金得主能達到 90% 的準確率,而 GPT-3 的準確率只能達到約 5%。
如果這一趨勢持續(xù)下去,那么機器學習模型距離獲得數(shù)學推理能力還很遙遠。
數(shù)據(jù)集
這部分介紹兩個新型數(shù)據(jù)集,一個是用于測試模型數(shù)學問題求解能力的 MATH 數(shù)據(jù)集,另一個是用于輔助預訓練的 AMPS 數(shù)據(jù)集。
MATH 數(shù)據(jù)集
MATH 數(shù)據(jù)集包含 12, 500 個數(shù)學問題(其中 7500 個屬于訓練集,5000 個屬于測試集),這些問題收集自 AMC 10、AMC 12、AIME 等數(shù)學競賽(這些數(shù)學競賽已經持續(xù)數(shù)十年,旨在評估美國最優(yōu)秀的年輕數(shù)學人才的數(shù)學問題求解能力)。與大多數(shù)之前的研究不同,MATH 數(shù)據(jù)集中的大部分問題無法通過直接應用標準 K-12 數(shù)學工具來解決,人類解決這類問題通常需要用到問題求解技術和「啟發(fā)式」方法。
基于這些數(shù)學問題,模型可以學習多種有用的問題求解啟發(fā)式方法,且每個問題都有逐步求解過程和最終答案。具備逐步求解過程的問題示例參見下圖 1:

該數(shù)據(jù)集的創(chuàng)建涉及以下重要步驟:
問題分類:該數(shù)據(jù)集中的問題難度不同,并涉及多個主題,包括算術、代數(shù)、數(shù)論、計數(shù)與概率、幾何、中級代數(shù)、預備微積分。研究者按照對人類而言從易到難的程度將問題難度等級標注為 1-5。
格式化:使用 LATEX 和 Asymptote 矢量圖語言將數(shù)學問題及其解進行統(tǒng)一格式化。
自動評估生成的答案:MATH 數(shù)據(jù)集的獨特設計使得研究者可以自動評估模型生成的答案,即使模型輸出空間非常大。
人類性能:為了估計人類性能,研究者從 MATH 測試集中隨機采樣了 20 個問題,交由高校學生回答。一位不喜歡數(shù)學的參與者答對了 8 道題(準確率 40%),兩位喜歡數(shù)學的參與者分別答對了 14 題和 15 題,一位在 AMC 10 數(shù)學競賽中拿到滿分并多次參加 USAMO 競賽的參與者答對了 18 道題,一位 IMO 三金得主也答對了 18 道題(準確率 90%)。這說明 MATH 數(shù)據(jù)集中的數(shù)學問題對于人類而言也是有一定難度的。
AMPS 數(shù)據(jù)集(可汗學院 + Mathematica)
預訓練數(shù)據(jù)會對性能產生極大影響,而數(shù)學是在線文本的一小部分,于是該研究創(chuàng)建了一個大型多樣化的數(shù)學預訓練語料庫。該預訓練數(shù)據(jù)集 Auxiliary Mathematics Problems and Solutions (AMPS) 包括許多問題及 LATEX 格式的逐步求解過程。
AMPS 數(shù)據(jù)集包含 10 萬個收集自可汗學院的數(shù)學問題,和約 500 萬通過手動設計 Mathematica 腳本生成的問題。該研究使用 Mathematica 的計算機代數(shù)系統(tǒng)生成數(shù)學問題,是為了便于操作分數(shù)、超越數(shù)和解析函數(shù)。
這些問題涉及多個主題,包括代數(shù)、微積分、計數(shù)與統(tǒng)計、幾何、線性代數(shù),以及數(shù)論(參見下表 1)。

實驗
模型性能
研究者通過實驗調查了模型在 MATH 數(shù)據(jù)集上的性能,發(fā)現(xiàn)即使最優(yōu)模型的準確率也很低。此外,與大多數(shù)基于文本的數(shù)據(jù)集不同,該數(shù)據(jù)集上的準確率增速隨著模型規(guī)模的擴大而越來越慢。如果這一趨勢繼續(xù),則要想在 MATH 數(shù)據(jù)集上取得較大進展,我們需要的不只是模型擴展,而是算法改進。
下表 2 表明,最小模型 GPT-2(0.1 billion 參數(shù)量,基線模型)在 MATH 數(shù)據(jù)集多個主題上的平均準確率為 5.4%,而 GPT-2(1.5 billion 參數(shù)量,參數(shù)量是基線模型的 15 倍)的平均準確率為 6.9%,相比基線提升了 28%。這表明與大部分其它基于文本的任務不同,在 MATH 數(shù)據(jù)集上增加模型參數(shù)確實有所幫助,但模型的絕對準確率仍然很低,且增速緩慢。
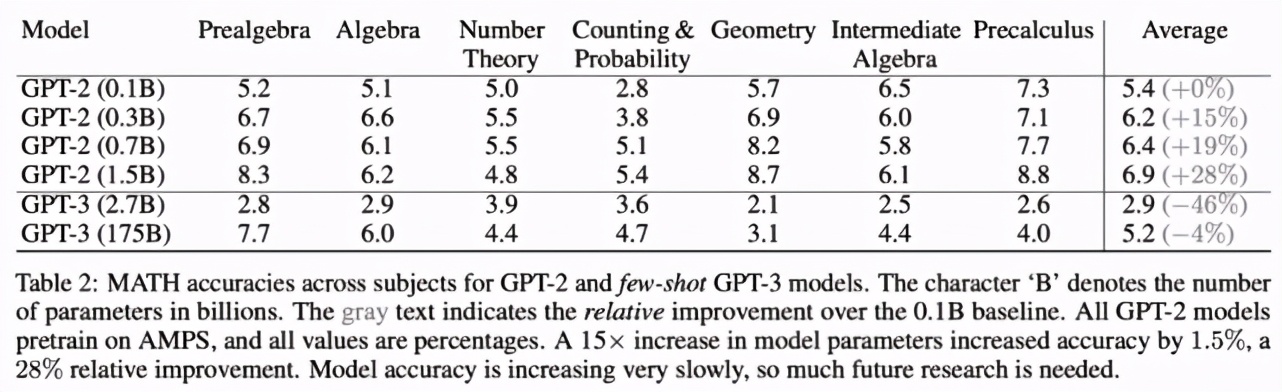
此外,研究者測試了使用 AMPS 預訓練的效果。未經 AMPS 預訓練時,GPT-2 (1.5B) 模型在 MATH 數(shù)據(jù)集上的準確率為 5.5%;而經過 AMPS 預訓練后,GPT-2 (1.5B) 在 MATH 數(shù)據(jù)集上的準確率為 6.9%(參見表 2),準確率提升了 25%。也就是說,AMPS 預訓練對準確率的提升效果相當于參數(shù)量 15 倍增加的效果,這表明 AMPS 預訓練數(shù)據(jù)集是有價值的。
逐步求解
研究者對逐步求解過程進行了實驗,發(fā)現(xiàn)模型在得到答案前先生成逐步求解過程會導致準確率下降。研究者利用 GPT-2 (1.5B) 進行評估,發(fā)現(xiàn)模型性能有所下降,從 6.9% 下降到了 5.3%。
研究者還對這些生成的逐步求解過程進行了定性評估,發(fā)現(xiàn)盡管很多步驟看似與問題相關,但其實存在邏輯問題。示例參見下圖 3、4:

圖 3:問題、GPT-2 (1.5B) 模型生成的逐步解、真值解。

圖 4:問題、生成解和真值解示例。
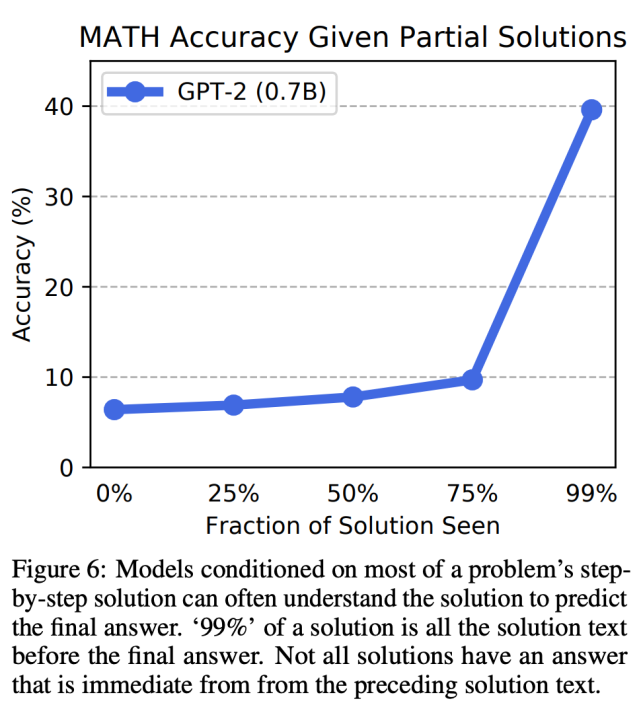
不過,研究人員發(fā)現(xiàn)逐步求解仍能帶來一定好處:提供部分真值逐步求解過程可以提升性能,在訓練過程中為模型提供逐步求解過程可以提升準確率。下圖 6 展示了 GPT-2 (0.7B) 模型使用不同部分求解過程的準確率變化。