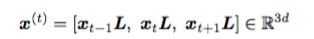DeepMind與谷歌又出大招!用神經網絡解決NP-hard的MIP問題
近日,DeepMind 與 Google Research 團隊共同發布了一項工作,用神經網絡與機器學習方法來解決混合整數規劃(MIP)問題!
論文地址:https://arxiv.org/pdf/2012.13349.pdf
在解決現實中遇到的大規模混合整數規劃(Mixed Integer Programming, MIP)實例時,MIP 求解器要借助一系列復雜的、經過數十年研究而開發的啟發式算法,而機器學習可以使用數據中實例之間的共享結構,從數據中自動構建更好的啟發式算法。
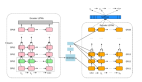
在這篇工作中,他們將機器學習應用于 MIP求解器的兩個關鍵子任務,生成了一個高質量的聯合變量賦值(joint variable assignment),并縮小了該變量賦值與最優賦值之間的目標值差距。他們構建了兩個對應的、基于神經網絡的組件,即 Neural Diving 與 Neural Branching,使其可用于基本的 MIP 求解器上,比如 SCIP。
其中,Neural Diving 學習一個深度神經網絡,為其整數變量生成多個部分賦值,并用 SCIP 來解決由此產生的未賦值變量的較小 MIP,以得到高質量的聯合賦值。而 Neural Branching 學習一個深度神經網絡,在分支定界中進行變量選擇決策,以用一棵小樹來縮小目標值的差距。這是通過模仿他們所提出的 Full Strong Branching(全強分支)的新變量來實現。
作者團隊將神經網絡在多個真實世界的數據集(包括兩個谷歌生產數據集和 MIPLIB)上分別進行了訓練,以進行評估。在所有數據集中,大多數實例在預求解后都有 10^3 至 10^6 個變量和約束,明顯大于以前的學習方法。
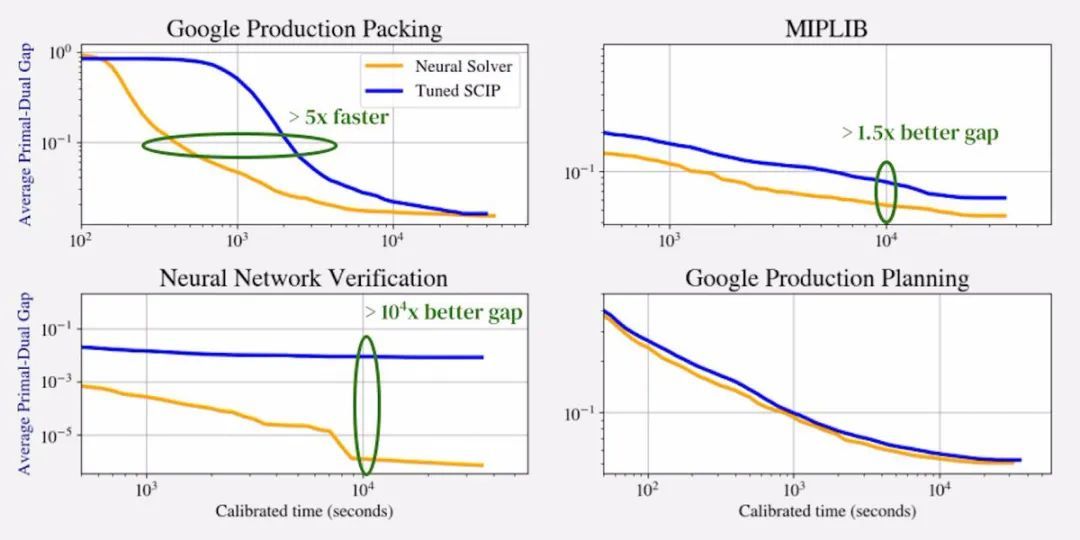
對比求解器與大時間限制下原問題與對偶問題在一組留出(hold-out)實例上的差距平均值,學習增強的 SCIP 在3個具有最大 MIP 的數據集(一共有5個數據集)上實現了 1.5x、2x 和 104x 的更好差距,在第4個數據集上以5x的速度更快實現 10% 的差距,并在第5個數據集上取得了與 SCIP 不相上下的表現。
該團隊介紹,據了解,他們的方法是第一個在大規模現實世界應用數據集和 MIPLIB 上都展示了比 SCIP 有更大進步的學習方法。
1、概念簡介
1.1 分支定界
常見的解決 MIP 過程是遞歸地構建搜索樹,在每個節點處分配部分整數,并使用每個節點所收集的信息最終收斂于最佳(或接近最佳)分配。在每一步,我們都必須選擇一個葉子節點,從中“分支”。在這個節點上,我們可以解決線性規劃(LP)松弛問題,將在該節點上的固定變量的范圍限制為它們的指定值。這為我們提供了該節點中所有子節點的真實目標值的有效下限。
如果這個界限大于已知的可行分配,那么我們就可以安全地修剪搜索樹的這一部分,因為該節點的子樹中不存在原問題的最優解。如果我們決定擴展這個節點,那么我們必須從該節點的一組未固定變量中選擇一個變量作為分支。一旦選擇了一個變量,我們就采取分支步驟,將兩個子節點添加到當前節點。一個節點有選定變量的域,該域會被約束為大于或等于其父節點處的 LP 松弛值的上限。另一個節點將所選變量的域約束為小于或等于其 LP 松弛值的下限。樹被更新,過程再次開始。
這個算法被稱為“分支定界”(branch-and-bound)算法。線性規劃是這個過程的主要工作,既可以在每個節點上導出對偶邊界,又可以為一些更復雜的分支啟發式算法確定分支變量。理論上,搜索樹的大小可以隨著問題的輸入大小呈指數增長,但在許多情況下,搜索樹可能很小,并且是一個提出節點選擇和變量選擇啟發式算法來使樹盡可能保持小的活躍研究領域。
1.2 原始啟發式
原始啟發式是一種嘗試找到可行但不一定最佳的變量賦值的方法。任何此類可行的賦值都提供了 MIP 最佳值的保證上限。在 MIP 求解期間的任何點找到的任何此類邊界都被稱為“原始邊界”。
原始啟發式可以獨立于分支定界運行,但它們也可以在分支定界樹中運行,并嘗試從搜索樹中的給定節點找到不固定變量的可行賦值。生成較低原始邊界的、更好的原始啟發式方法允許在分支定界過程中修剪更多的樹。簡單的四舍五入就是原始啟發式的一個例子。另一個例子是潛水(diving),試圖通過深度優先的方式從給定節點中探索搜索樹來找到可行的解決方案。
1.3 原始-對偶間隙
在運行分支定界時,我們會跟蹤全局原始邊界(任何可行分配的最小目標值)和全局對偶邊界(分支定界樹所有葉子的最小對偶邊界)。我們可以結合這些來定義次優間隙(sub-optimality gap):
- 間隙=全局原始邊界-全局對偶邊界
構造的間隙總是非負的。如果它為零,那么我們已經解決了問題,與原始邊界對應的可行點是最優的,而對偶邊界是最優性的證明。在實踐中,當相對間隙(即以某種方式歸一化)低于某個依賴于應用的數量時,我們會終止分支定界,并生成最佳的已尋原始解決方案作為近似最優解決方案。

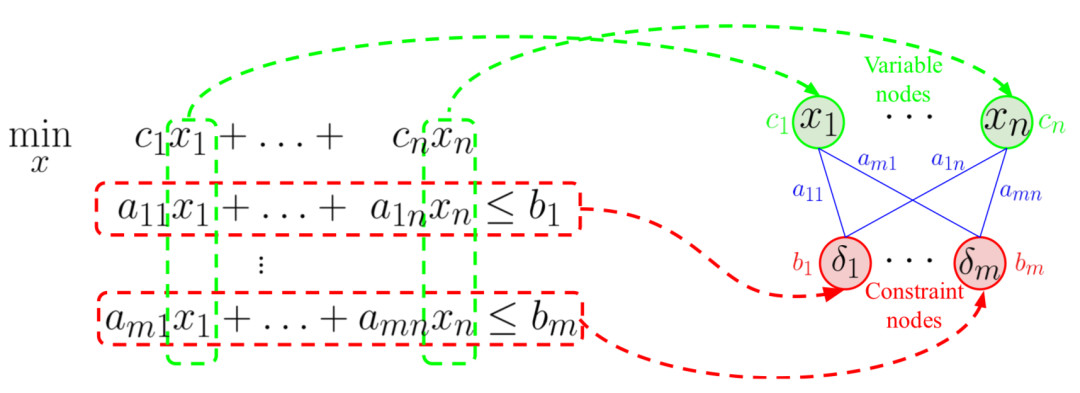
圖注:用作神經網絡輸入的 MIP 的二部圖表示。n 個變量的集合 {x1,...,xn} 和 m 個約束的集合 {δ1,...,δm} 形成了二部圖的兩組節點。系數被編碼為節點和邊的特征。
2、論文介紹
混合整數規劃 (MIP) 是 NP-hard 問題中的一類,它的目標是在線性約束下將線性目標最小化,同時使部分或全部變量均為整數值,在容量規劃、資源分配與裝箱等等現實場景中得到了廣泛應用。
該方向的大量研究與工程投入都集中在了開發實用求解器上,比如 SCIP、CPLEX、Gurobi 和 Xpress。這些求解器都是使用復雜的啟發式算法來指導求解 MIP 的搜索過程。一個求解器在特定應用上的表現主要是取決于該求解器的啟發式算法與該應用的匹配程度。
在這篇工作中,作者團隊展示了機器學習可用于從 MIP 實例數據集中自動構建有效的啟發式算法。當一個應用需要解決具有不同問題參數的同一高級語義問題中的大量實例時,機器學習便派上了用場。
這篇工作中,此類“同質”數據集的例子包括:1)優化選擇電網中的發電廠,以滿足需求(O'Neill 2017),其中,電網拓撲保持不變,而需求、可再生能源發電等則因情況而異;2) 解決谷歌生產系統中的包裝問題,其中,待打包的“物件”(items)和“箱子”(bins)的語義基本保持不變,但它們的尺寸大小會根據不同的情況而有所變化。
即使是結合了許多語義不同的問題的“異構”數據集,比如 MIPLIB 2017,也可以擁有跨實例的結構,用于學習更好的啟發式算法。現成的 MIP 求解器無法自動構建啟發式算法來利用這種結構。在具有挑戰性的應用場景中,用戶可能會依賴專家來手動設計此類啟發式算法,或放棄潛在的大幅性能改進。機器學習提供了大幅改進的可能性,且無需使用特定應用場景的專業知識。
這篇工作證明了,機器學習可以構建為特定數據集定制的啟發式算法,其性能會明顯優于在 MIP 求解器中所使用過的經典方法,包括最先進的非商業求解器 SCIP 7.0.1 。
他們的方法將機器學習應用于 MIP 求解器的兩個關鍵子任務:a) 輸出能滿足約束條件的所有變量的賦值(如果存在這樣的賦值);b)證明變量賦值與最優賦值之間的目標值差距范圍。這兩個任務決定了該方法的主要組件,即 Neural Diving 與 Neural Branching(見圖1)。
圖注:我們的方法構建了兩個在 MIP 求解器中使用、基于神經網絡的組件,即 Neural Diving 與 Neural Branching,并將兩者結合,得到了一個為特定 MIP 數據集量身定做的神經求解器(Neural Solver)。
Neural Diving:該組件可找到高質量的聯合變量賦值。它是原始啟發式算法 (Berthold 2006) 的一個示例,而原始啟發式是一類對有效 MIP 求解器十分關鍵的搜索啟發式算法 (Berthold 2013)。
作者團隊訓練一個深度神經網絡來生成輸入 MIP 的整數變量的多個部分真值(partial assignments)。其余未賦值的變量定義了較小的“sub-MIPs”,它們是用現成的 MIP 求解器(例如 SCIP)求解來完成賦值。如果計算預算允許,sub-MIPs 可以并行求解。模型經過訓練,使用現成求解器離線收集的訓練示例,為靈活的、擁有更優目標值的賦值提供更高的概率。模型是基于所有可用的可行賦值而不是最優賦值來進行學習,且不一定要用到最優賦值(因為收集的成本可能非常昂貴)。
Neural Branching:該組件主要用于縮小最好賦值與最優賦值的目標值之間的差距。
在整數變量上,MIP 求解器使用了一種樹搜索的形式,即“分支定界”,逐漸收緊邊界并幫助尋找可行的賦值。在給定節點上,分支變量的選擇是決定搜索效率的關鍵因素。
他們訓練了一個深度神經網絡策略來模仿專家策略所做出的選擇。模仿目標是一個著名的啟發式算法,稱為“全強分支”(FSB),實踐已證明,FSB 可以生成小型搜索樹。雖然對實際的 MIP 求解來說,它的計算成本往往過高,但它仍可以被當成一種緩慢且昂貴的一次性計算,用于離線生成模仿學習數據。一旦經過訓練,這個神經網絡就能夠在測試時以一小部分計算成本來接近專業表現。即使是在離線數據的生成上,基于 CPU 的 FSB 實現在大規模 MIP 上也可能過于昂貴。他們用交替方向乘子法 (ADMM) 開發了 FSB 的變體,可以通過在 GPU 上以批處理方式執行所需的計算來擴展到大規模 MIP。
DeepMind與Google Research的團隊在許多包含大規模 MIP 的數據集上對這個方法進行了評估,包括來自 Google 生產系統的兩個數據集,以及 MIPLIB(一個異構數據集和標準基準)。
來自所有數據集的大多數 MIP 組合集在預求解后都有 10^3-10^6 個變量和約束,明顯大于早期工作(Gasse et al. 2019, Ding et al. 2020)。一旦 Neural Diving 與 Neural Branching 模型在給定數據集上進行了訓練,它們會被整合到 SCIP 中,形成專門針對該數據集的“神經求解器”(Neural Solver)。SCIP是基線,重點參數分別在每個數據集上經過網格搜索進行調整,他們將其稱為“Tuned SCIP”。
比較 Neural Solver 和 Tuned SCIP 在一組hold-out實例上原問題對偶問題的差距平均值 (如圖2),在他們所評估的、具有最大 MIP 的4個數據集(一共有5個數據集)上,神經求解器(Neural Solver)在相同的運行時間內提供了明顯更好的差距,或在更少時間內提供了相同的差距,同時在第5個數據集上媲美 Tuned SCIP 的表現。他們介紹,據他們所知,這是第一項在大規模現實世界應用數據集和 MIPLIB 上,使用機器學習比使用 SCIP 具有更大改進的工作。
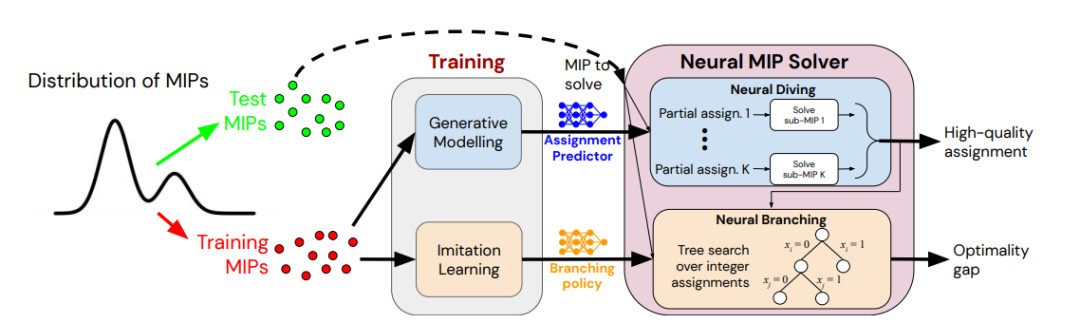
圖 2:論文的主要結果:他們的方法(Neural Branching + Neural Divin)在原問題與對偶問題的差距上與 SCIP 媲美,或優于 SCIP,在留出實例上不相上下。
Tuned SCIP 是他們比較的基線,因為他們使用 SCIP 作為整合學習啟發式算法的基礎求解器。
作為基礎求解器,SCIP 提供了:a) 用于集成學習模型的內部狀態的深入訪問權限;b) 并行運行大規模求解實例來進行大規模評估的許可授權。
作者表示,他們無法使用具有這些功能的商業求解器,所以它們相當于不可用。他們已經在兩個數據集上對 Gurobi 與 Neural Diving 進行了部分比較,其中 Gurobi 作為 sub-MIP 的求解器。對比原始差距在一組保留實例上的平均值,具有并行 sub-MIP 求解的 Neural Diving 在兩個數據集上達到 1% 的平均原始間隔比 Gurobi 的時間少 3 倍和 3.6 倍。
他們還將 Neural Diving 的修改版本應用于 MIPLIB 中“開放”實例的子集,以找到三個新的最著名任務來擊敗商業求解器。一些早期的工作專注于學習原始啟發式算法。與它們不同的是,Neural Diving 將預測變量賦值的問題看作生成建模問題提出,提供了一種原則性方法來學習所有可用的可行賦值,并在測試時間內生成部分真值。
一些工作也著眼于學習分支策略。其中,許多都像DeepMind這個團隊一樣專注于學習模仿 FSB。與它們不同的是,Neural Branching 使用了更可擴展的方法來計算使用 GPU 的目標策略,與基于 CPU 的 FSB 實現相比,這允許它在相同的時間限制內從更大的實例中生成更多的模仿數據。這個工作還超越了早期獨立研究學習個體啟發式的工作,通過在求解器中結合學習的原始啟發式和學習的分支策略,在大規模實際應用數據集和 MIPLIB 上實現了明顯更優的性能。
3、論文貢獻
這個工作的主要貢獻如下:
- 提出了Neural Diving。這是一種基于學習的新方法,可以為 MIP 生成高質量的聯合變量賦值。在同類數據集上,Neural Diving 在留出實例上實現了 1% 的平均原始差距,比 Tuned SCIP 快了 3-10 倍。在一個數據集上,Tuned SCIP 在時限內沒能達到 1% 的平均原始差距,而 Neural Diving 做到了。
- 提出了Neural Branching,通過模仿基于 ADMM 的新可擴展專家策略來學習在分支定界算法中使用的分支策略。在評估時所使用的兩個數據集上,由于實例規模(如有大于105個變量)或每次的迭代時間很長,FSB很慢,ADMM 專家在相同的運行時間內生成了 1.4 倍和 12 倍訓練數據。學習策略在四個數據集上顯著優于 SCIP 的分支啟發式算法,在大時間限制下的留出實例上平均對偶差距提高了 2-20 倍,并在其他數據集上取得了可媲美的性能。
- 將 Neural Diving 與 Neural Branching 結合起來,在具有最大 MIP 的4個數據集(共有5個數據集)中的平均原始對偶差距上獲得了明顯比 SCIP 更好的性能,同時在第5個數據集中達到與 SCIP 不相上下的性能。
此外,他們還開源了一個用于神經網絡驗證的數據集(第 4、12.6 節),希望有助于進一步研究 MIP 的新學習技術。
4、結論
這項工作證明了機器學習在大規模現實世界應用數據集和 MIPLIB 上能夠顯著提高 MIP 求解器性能的長期潛力。我們相信,隨著模型和算法的進一步改善,這個方法會有更大的改進。
一些在未來有前景的研究方向是:
- 學習切割:使用機器學習更好地選擇和生成切割是性能改進的另一個潛在技術。
- 熱啟動模型:學習模型在 MIPLIB 上的強勁表現表明,它可以學習在不同 MIP 中都能很好地工作的啟發式方法。這可用于克服應用場景中的“冷啟動”問題,即應用中早期可用的訓練數據量可能太少而無法訓練好的模型。我們可以從使用在異構數據集上訓練的模型開始,并在為應用收集更多數據時,將它們用作通往更專業模型的橋梁。
- 強化學習:使用蒸餾或行為克隆獲得的性能是由現有的最佳專家提供,而強化學習 (RL) 可能會超過它。高效探索、長期信用分配和學習的計算可擴展性是將 RL 應用于大規模 MIP 的關鍵挑戰。解決這些問題可以帶來更大的性能改進。
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。