教自動編碼器學會「自我糾正」,DeepMind提出語言模型“SUNDAE”
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
一直以來,自回歸語言模型(Autoregressive model,AR)在文本生成任務中表現都相當出色。
現在,DeepMind通過教自動編碼器學會“自我糾正”,提出了一個叫做“圣代”(SUNDAE)的非自回歸模型。
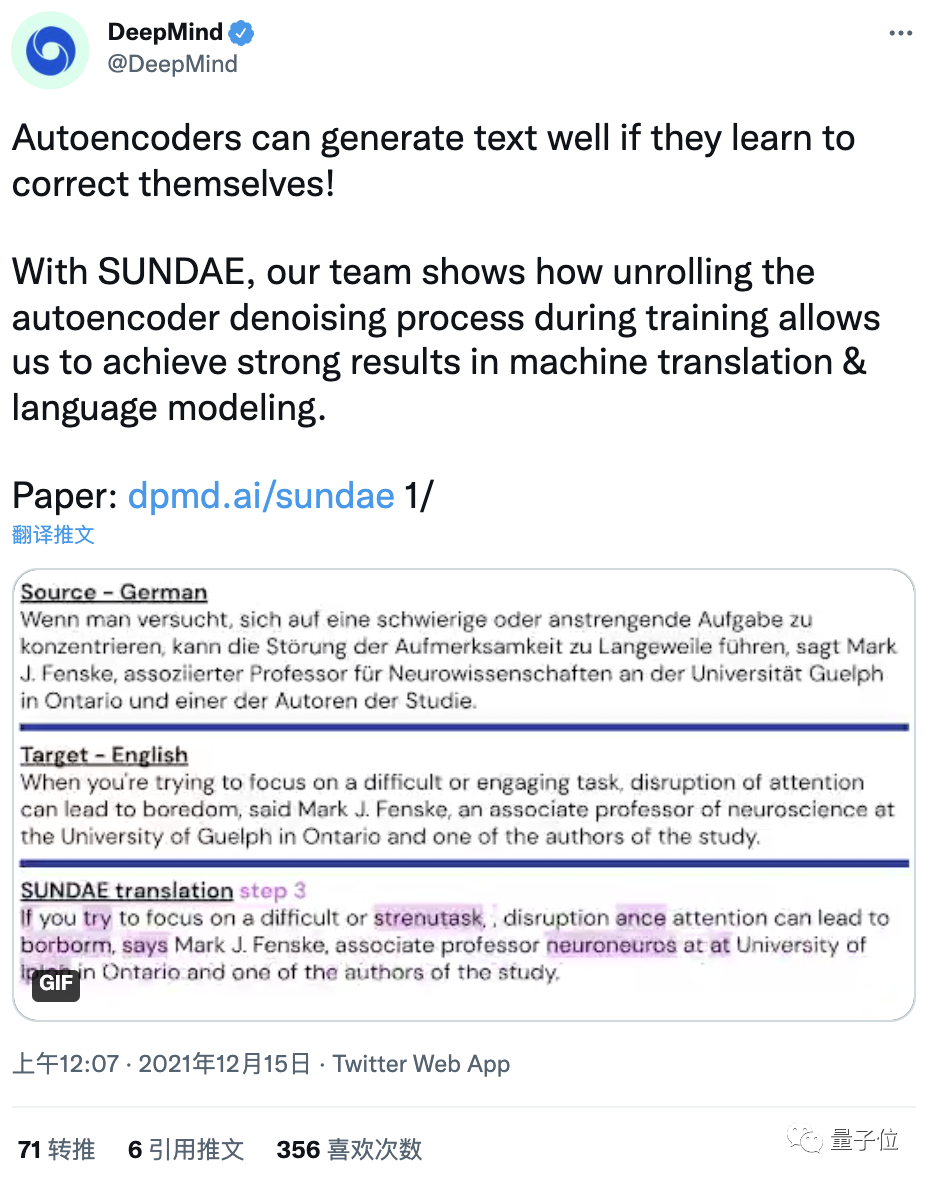
它不僅能在WMT’14英德互譯任務中取得非自回歸模型中的SOTA,還表現出與自回歸模型相當的性能。
更厲害的是,還能輕松做到自回歸模型做不到的事兒——文字補全。

要知道,非自回歸模型一直不被看好。
而這個“圣代”的文字補全功能,也為人類和機器共同編輯、創作文本提供了新的途徑。
非自回歸語言模型“圣代”
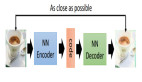
“圣代”全名“逐步展開降噪自動編碼器”(Step-unrolled Denoising Autoencoder,SUNDAE),作為一種新的文本生成模型,它不依賴于經典的自回歸模型。
與降噪擴散技術(denoising diffusion)類似,“圣代”在訓練期間采用展開降噪(unrolled denoising),將一系列token重復應用,從隨機輸入開始,每次都對其進行改進,直至收斂。
這就是所謂的“自我糾正”過程。

下面用一張圖來說明一下降噪和展開降噪的區別。
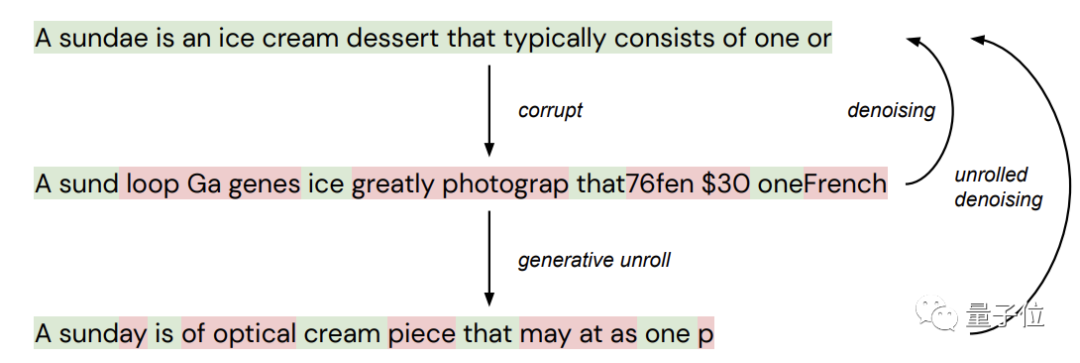
第一行為原始文本,它被隨機“污染”(corrupt)后產生新的文本(第二行),其中綠色的token代表“未污染”文本,紅色代表“污染”文本。
這個中間文本再通過降噪(從生成模型中采樣),生成底部的又一個“污染”文本。
標準降噪自動編碼器只學習從中間文本到頂部文本的映射,逐步展開降噪自動編碼器(“圣代”)則會學習從底部到頂部的映射。
而在文本生成期間,網絡遇到的大多數文本都并非像上圖中間那樣,而是底部那種,所以展開降噪是非常有用的。
此外,研究人員還提出了一個簡單的改進算子,它能實現比降噪擴散技術收斂所需的更少的迭代次數,同時在自然語言數據集上定性地生成更好的樣本。
直白的說,“圣代”采用的方法讓文本合成的質量和速度都變得可控了。
在機器翻譯和文本生成任務上表現如何?
下面就來看看“圣代”的具體表現。
研究人員首先在機器翻譯基準上評估“圣代”。
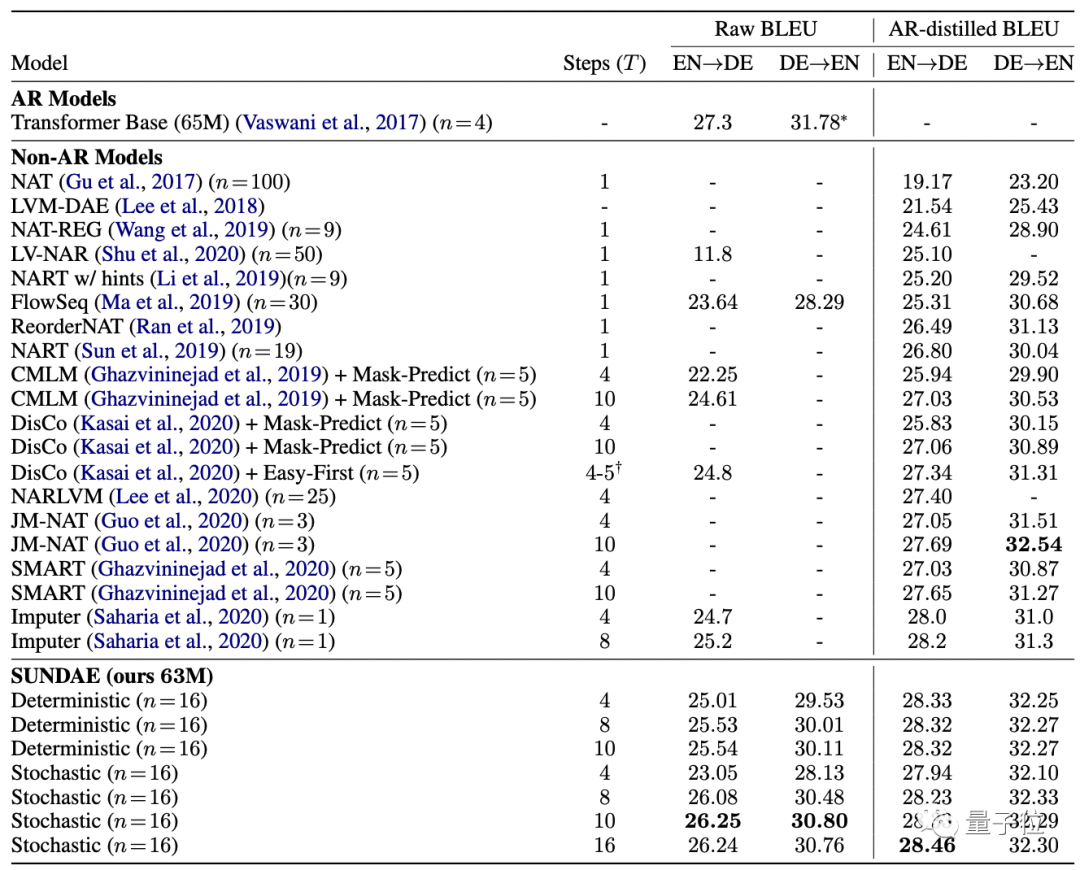
使用BLEU分數作為衡量標準,將“圣代”在WMT’14德英互譯任務上的翻譯質量與自回歸模型(AR)和非AR模型進行比較。
結果發現,在不使用序列級知識蒸餾等技術的情況下,“圣代”的性能幾乎與AR模型相當,并且打敗了所有非AR模型。
接著是對“圣代”在文本生成任務上的評估。
研究人員在大型高質量公開數據集 Colossal Clean Common Crawl (C4) 上訓練“圣代”。
模型一共包含335M參數,24層,embedding size為1024 , hidden size為4096 , 以及16 個attention head,使用bacth size為4096的Adam optimizer訓練了多達40萬步。
最終生成的文本如下,未經cherry pick:
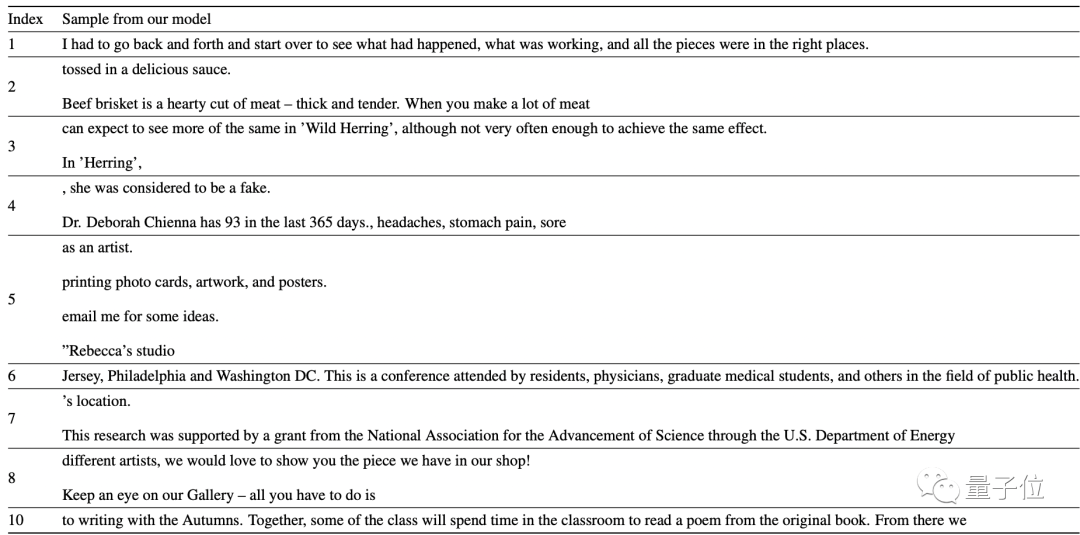
這10句里面,除了第4,都挺合理。
不過由于C4數據集來自網絡,所以無論是訓練集還是生成的最終結果,換行符都挺多。
此外,由于“圣代”模型的非自回歸性,研究人員也測試了它的文本“修復”能力。
要知道,這對于只能從左到右按序生成的AR模型來說根本就辦不到。
結果如下(cherry-pick過):
- C4數據集

- GitHub上的Python程序組成的數據集

大家覺得這效果如何?語法和邏輯似乎都沒有問題。
更多數據和內容歡迎戳下方鏈接。
論文地址:
https://arxiv.org/abs/2112.06749