













Python 高級算法和數據結構:集合的快速查詢與合并

在代碼設計中時常面對這樣的場景,給定兩個元素,我們需要快速判斷他們是否屬于同一個集合,同時不同的集合在需要時還能快速合并為一個集合,例如我們要開發一個社交應用,那么判斷兩個用戶是否是朋友關系,或者兩人是否屬于同一個群就需要用到我們現在提到的功能。
這些功能看似簡單,但有個難點在于你要處理的“足夠快”,假設a,b兩個元素分別屬于集合A,B,判斷它們是否屬于同一個集合的直接做法就是遍歷集合A中所有元素,看看是否能找到b,如果集合A中包含n個元素,那么該做法的時間復雜度就是O(n),當集合元素很多,而且判斷的次數也很多時,這樣的做法效率就會很低,本節我們要看看能不能找到次線性的算法。
我們先看復雜度為O(n)的算法邏輯,假設我們有6個元素,編號分別為0到6,我們可以使用隊列來模擬集合,屬于同一個集合的元素就存儲在同一個隊列中,然后每個元素通過哈希表映射到隊列頭,如下圖所示:
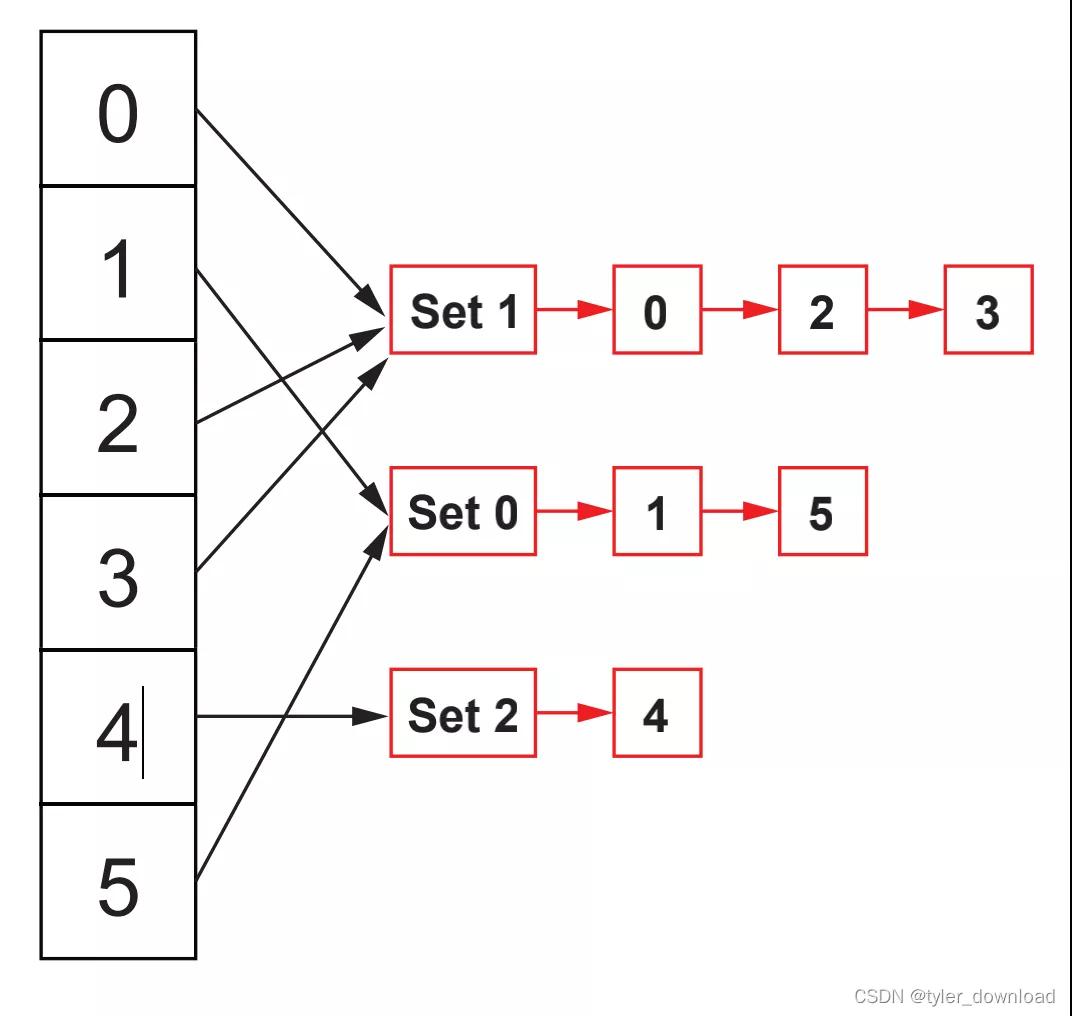
在這種數據結構下,查詢兩個元素是否屬于同一個集合,那么只要通過哈希表找到各自元素所在隊列的頭部,判斷頭部是否一致即可,我們用areDisjoint(x,y)來表示兩個元素是否屬于一個集合,那么在當前數據結構下areDisjoint的時間復雜度是O(1)。
如果要合并兩個元素所在集合,我們用merge(x,y)來表示,那么在當前結構下,我們只要找到x和y對應的隊列頭部,然后從x所在隊列的頭部遍歷到最后一個元素,然后將最后一個元素的next指針執行y所在的隊列頭部,如下圖所示:
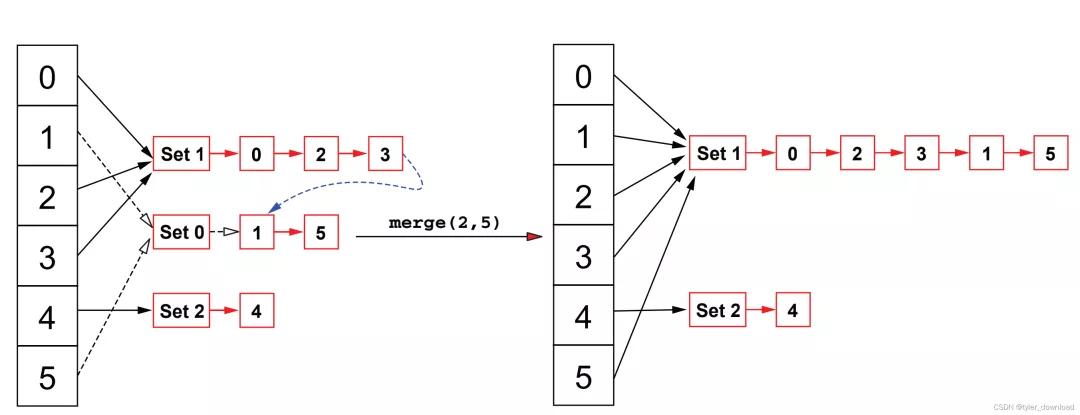
同時我們還需要做一個操作,那就是修改第二個集合中每個元素映射的隊列頭部,因此在當前結構下,merge(x,y)對應時間復雜度為O(n),因為從隊列頭遍歷到末尾是O(n),同時遍歷y所在集合每個元素,修改他們映射的隊列頭,時間復雜度也是O(n)。
現在問題是我們能否將合并所需要的時間進行優化。我們注意到合并時有兩個步驟很耗時,一是從隊列走到隊尾,二是修改第二個集合中每個元素指向的隊列頭。所以耗時其實是因為我們使用隊列來表示集合所導致。為了優化時間,我們將隊列換成多叉樹,如下圖所示:
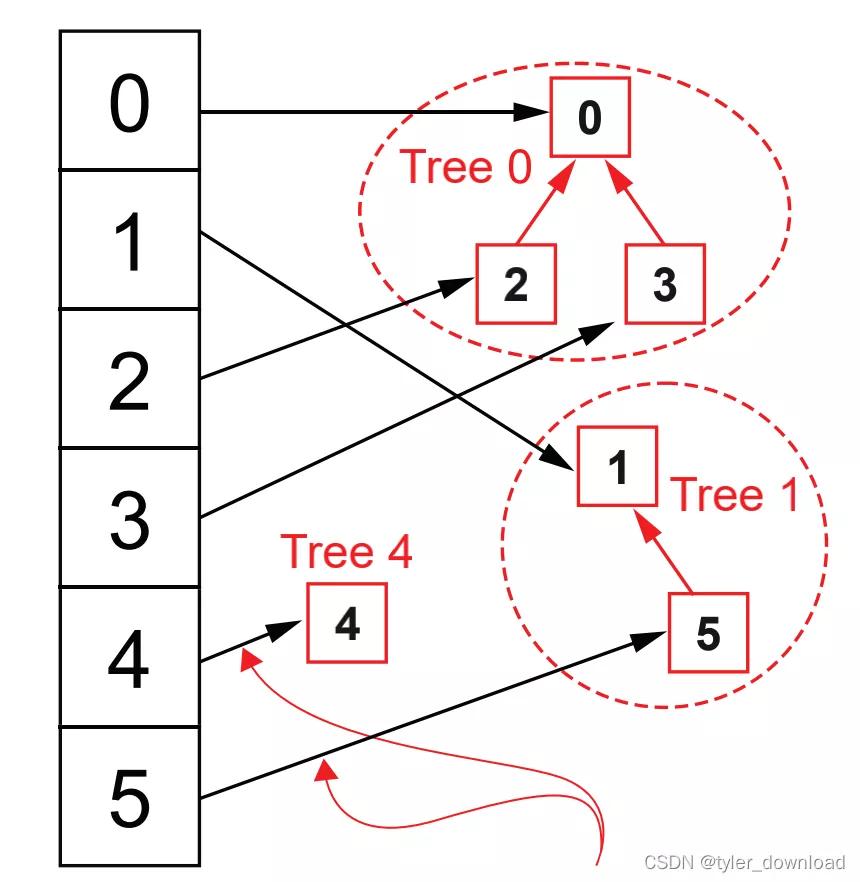
此時我們不再使用哈希表來將元素映射到隊列頭部,而是將同一個集合的元素安插到同一個多叉樹中,要判斷兩個元素是否屬于同一集合,我們只要沿著元素的父節點指針往上走一直找到樹的根節點,如果找到相同的根節點,那么兩個元素就屬于同一集合,對于排序二叉樹而言,樹的高度為O(lg(n)),n是樹的節點數,于是判斷兩個元素是否屬于同一集合所需時間復雜度為O(lg(n))。
當需要合并兩個元素對于的集合時,我們分別找到兩個元素對于的根節點,然后將高度較低的那棵樹的根節點作為高度較高那棵樹的子節點,這個處理對效率很重要,后面我們會進一步研究,樹合并的情形如下圖所示:
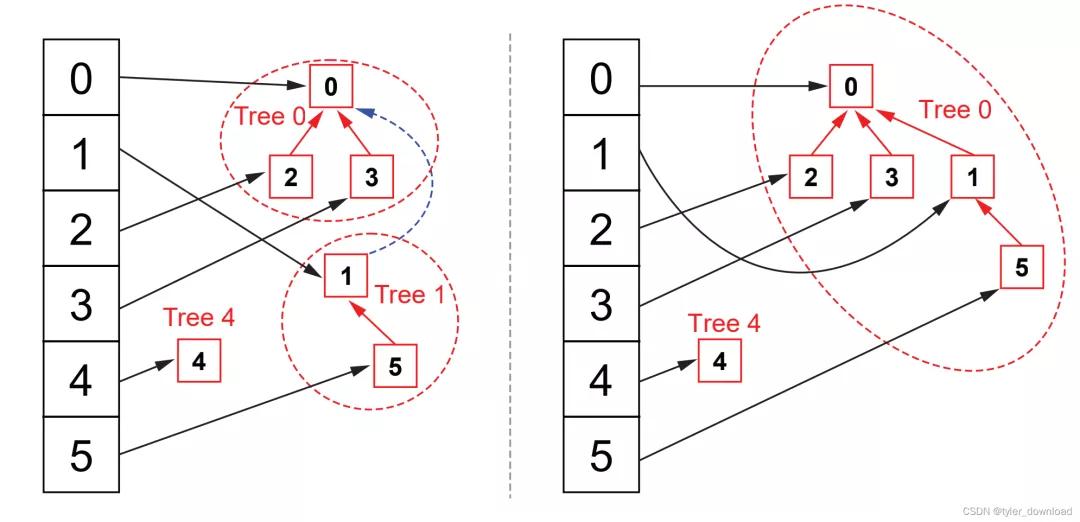
下面我們先看看代碼實現:
- # This is a sample Python script.
- # Press ⌃R to execute it or replace it with your code.
- # Press Double ⇧ to search everywhere for classes, files, tool windows, actions, and settings.
- class Element:
- def __init__(self, val : int):
- self.val = val
- self.parent = self #元素在創建時自己形成一個單獨集合,因此父節點指向自己
- def value(self):
- return self.val
- def parent(self):
- return self.parent
- def set_parent(self, parent):
- assert parent is not None
- self.parent = parent
- class DisjontSet:
- def __init__(self):
- self.hash_map = {}
- def add(self, elem : Element):
- assert elem is not None
- if elem.value() in self.hash_map:
- return False
- self.hash_map[elem.value()] = elem
- return True
- def find_partition(self, elem : Element):
- #返回元素所在集合的根節點
- assert elem is not None or elem.value() in self.hash_map
- parent = elem.parent()
- if parent != elem: #遞歸查找根節點,樹的高度為lg(n),所以這里查找的時間復雜度為lg(n)
- parent = self.find_partition(parent)
- return parent
- def are_disjoint(self, elem1 : Element, elem2 : Element):
- #判斷兩個元素是否屬于同一集合只要判斷他們再哈希表中映射的根節點是否同一個
- root1 = self.find_partition(elem1)
- root2 = self.find_partition(elem2)
- return root1 is not root2
- def merge(self, elem1 : Element, elem2 : Element):
- root1 = self.find_partition(elem1)
- root2 = self.find_partition(elem2)
- if root1 is root2:
- #兩個元素屬于同一個集合
- return False
- root2.setParent(root1)
- self.hash_map[root2.value()] = root1 #設置root2對應的父節點
- # Press the green button in the gutter to run the script.
- if __name__ == '__main__':
- # See PyCharm help at https://www.jetbrains.com/help/pycharm/
由于我們將集合的表示從隊列改為了多叉樹,因此集合的查找與合并對應復雜度為O(lg(n)),現在問題是我們能否繼續改進效率。當前merge函數耗時在于我們要通過parent指針一直爬到根節點,如果能讓parent指針直接指向根節點那么不就省卻向上爬的時間開銷嗎,這種直接將下層節點父指針直接指向根節點的辦法叫路徑壓縮,如下圖所示:
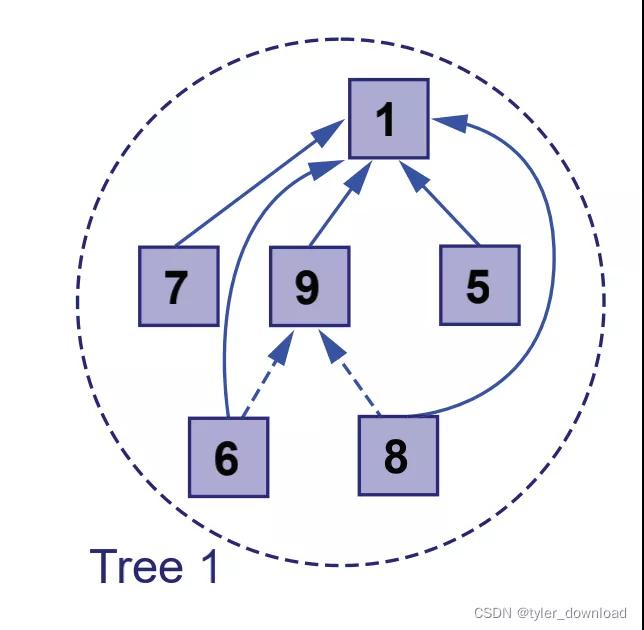
從上圖看到,節點6,8的父節點原來是9,它所在集合的根節點是1,于是我們直接將原來指向9的指針直接指向根節點1,這樣以后在合并或查詢集合時我們就可以省掉向上爬的時間開銷。還有一個問題在上面代碼中兩棵樹合并問題,我們僅僅是把root2的父指針指向root1,這么做會存在合并后樹不平衡問題,也就是合并后的左右子樹高度可能相差較大,這種情況也會對效率產生不利影響,如下圖所示:
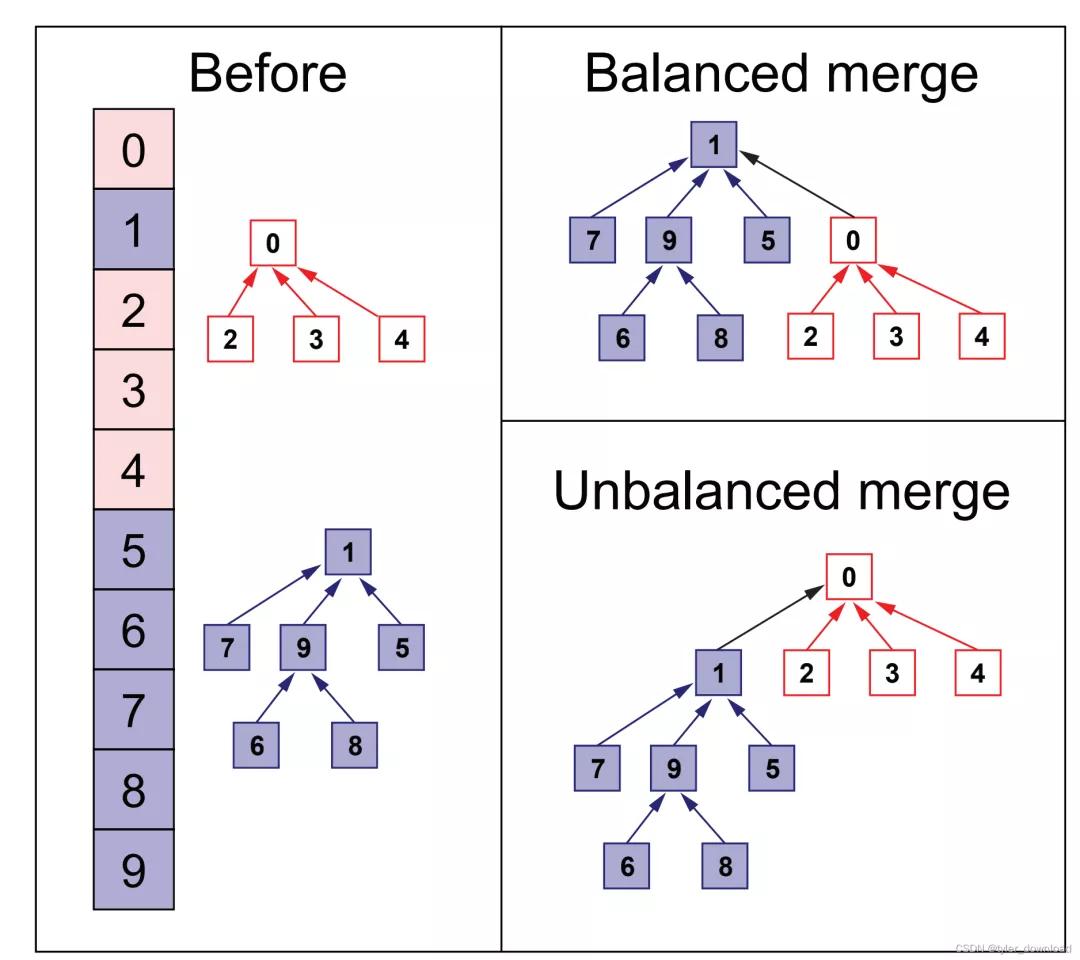
可以看到右下角合并后左右子樹高度差異大,于是節點,6,8找到根節點0所需的時間就要比2,3,4要多,但形成右上角的情況時,葉子節點6,8和2,3,4找到根節點的時間就差不多,這樣就有利于效率的提高,所以我們還需要記錄下樹的高度,在合并時要將高度小的樹合向高度高的樹,因此代碼修改如下:
- class Element:
- def __init__(self, val : int):
- self.val = val
- self.parent = self #元素在創建時自己形成一個單獨集合,因此父節點指向自己
- self.rank = 1 #表示樹的高度
- def value(self):
- return self.val
- def parent(self):
- return self.parent
- def set_parent(self, parent):
- assert parent is not None
- self.parent = parent
- def get_rank(self):
- return self.rank
- def set_rank(self, rank):
- assert rank > 1
- self.rank = rank
然后我們需要修改find_partition的做法
- def find_partition(self, elem : Element):
- #返回元素所在集合的根節點
- assert elem is not None or elem.value() in self.hash_map
- parent = elem.parent()
- if parent is elem: #已經是根節點
- return elem
- parent = self.find_partition(elem) #獲得集合的根節點
- elem.set_parent(parent) #路徑壓縮直接指向根節點
- return parent #返回根節點
注意到find_partion的實現中有遞歸過程,如果當前節點不是根節點,那么遞歸的查詢根節點,然后把當前節點的parent指針直接指向根節點,我們看到這步修改所需的時間復雜度跟原來一樣都是lg(n)。
接下來我們要修改merge的實現:
- def merge(self, elem1 : Element, elem2 : Element):
- root1 = self.find_partition(elem1)
- root2 = self.find_partition(elem2)
- if root1 is root2: # 兩個元素屬于同一個集合
- return False
- new_rank = root1.get_rank() + root2.get_rank()
- if root1.get_rank() >= root2.get_rank(): # 根據樹的高度來決定合并方向
- root2.set_parent(root1)
- root1.set_rank(new_rank)
- else:
- root1.set_parent(root2)
- root2.set_rank(new_rank)
- return True
這種改進后,在m次指向find_partion和merge調用時所需要的時間是O(m),也就是說在改進后,當大量調用find_partion和merge時,這些調用的平均耗時降到了O(1),也就是說路徑壓縮后,其效果在大批量的調用查找集合和合并集合操作時能出現非常顯著的效率提升,其對應的數學證明非常負責,我們暫時忽略調。我們可能對這里的效率提升感受不到,但想想微信中對兩個人是否屬于同一個群的調用一天至少也有千萬乃至上億次吧,因此這里的改進能大大的改進服務器的處理效率。
完整代碼在這里
https://github.com/wycl16514/python_disjoint_set.git



























