大模型「上車」關鍵一步:全球首個語言+自動駕駛開源數據集來了
作者:汽車人
在模型中,我們提出了一個具有思維圖能力的AD視覺語言模型,以產生更好的規劃結果。目前,數據集的演示已經發布,完整的數據集和模型將在未來發布。
DriveLM是一個基于語言的驅動項目,它包含一個數據集和一個模型。通過DriveLM,我們介紹了自動駕駛(AD)中大型語言模型的推理能力,以做出決策并確保可解釋的規劃。
在DriveLM的數據集中,將人工書寫的推理邏輯作為連接,促進感知、預測和規劃(P3)。在模型中,我們提出了一個具有思維圖能力的AD視覺語言模型,以產生更好的規劃結果。目前,數據集的演示已經發布,完整的數據集和模型將在未來發布。
項目鏈接:https://github.com/OpenDriveLab/DriveLM
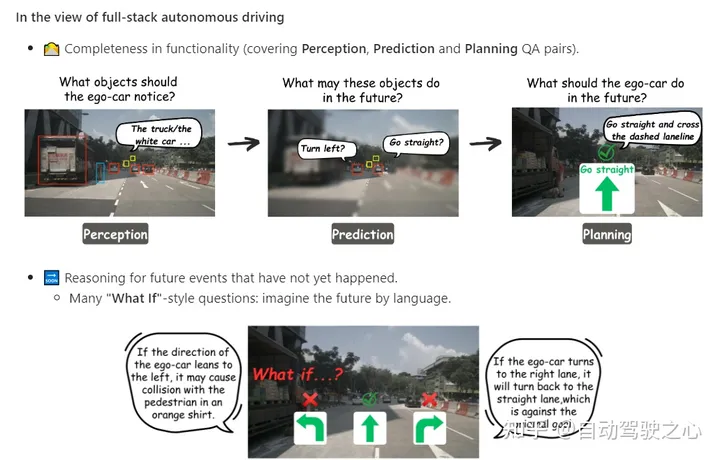

What is Graph-of-Thoughts in AD?
數據集最令人興奮的方面是,P3中的問答(QA)以圖形風格的結構連接,QA對作為每個節點,對象的關系作為邊。
與純語言的思維樹或思維圖相比,我們更傾向于多模態。在AD域中這樣做的原因是,從原始傳感器輸入到最終控制動作,每個階段都定義了AD任務。
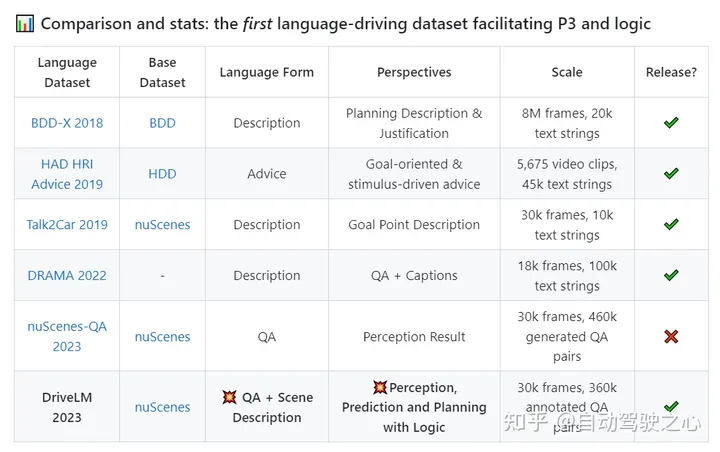
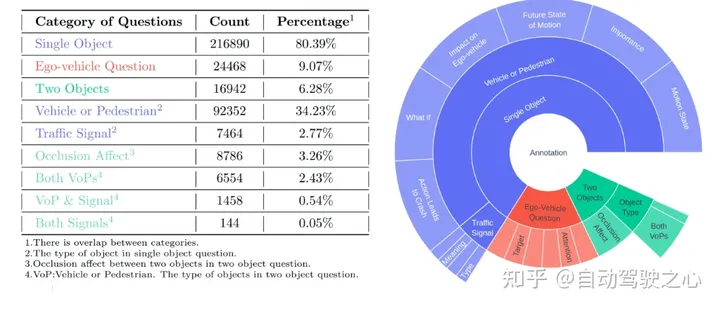
DriveLM數據集中包含什么?
基于主流的nuScenes數據集構建我們的數據集。DriveLM最核心的元素是基于幀的P3 QA。感知問題需要模型識別場景中的對象。預測問題要求模型預測場景中重要對象的未來狀態。規劃問題促使模型給出合理的規劃行動,避免危險的行動。
標定過程如何?
- 關鍵幀選擇。給定一個剪輯中的所有幀,注釋器將選擇需要注釋的關鍵幀。標準是,這些框架應該涉及自車運動狀態的變化(變道、突然停車、停車后啟動等)。
- 關鍵對象選擇。給定關鍵幀,注釋器需要拾取周圍六個圖像中的關鍵對象。標準是這些物體應該能夠影響自車(交通信號燈、過街行人、其他車輛)
- 問答注釋。給定這些關鍵對象,我們會自動生成關于感知、預測和規劃的單個或多個對象的問題。更多細節可以在我們的演示數據中找到。
責任編輯:張燕妮
來源:
自動駕駛之心