













北大最新多模態大模型開源:在混合數據集上訓練,無需修改直接用到圖像視頻任務
訓完130億參數通用視覺語言大模型,只需3天!
北大和中山大學團隊又出招了——在最新研究中,研究團隊提出了一種構建統一的圖片和視頻表征的框架。
利用這種框架,可以大大減少VLM(視覺語言大模型)在訓練和推理過程中的開銷。

具體而言,團隊按照提出的新框架,訓練了一個新的VLM:Chat-UniVi。
Chat-UniVi能在混合圖片和視頻數據的情況下進行訓練,并同時處理圖片任務和視頻理解任務。
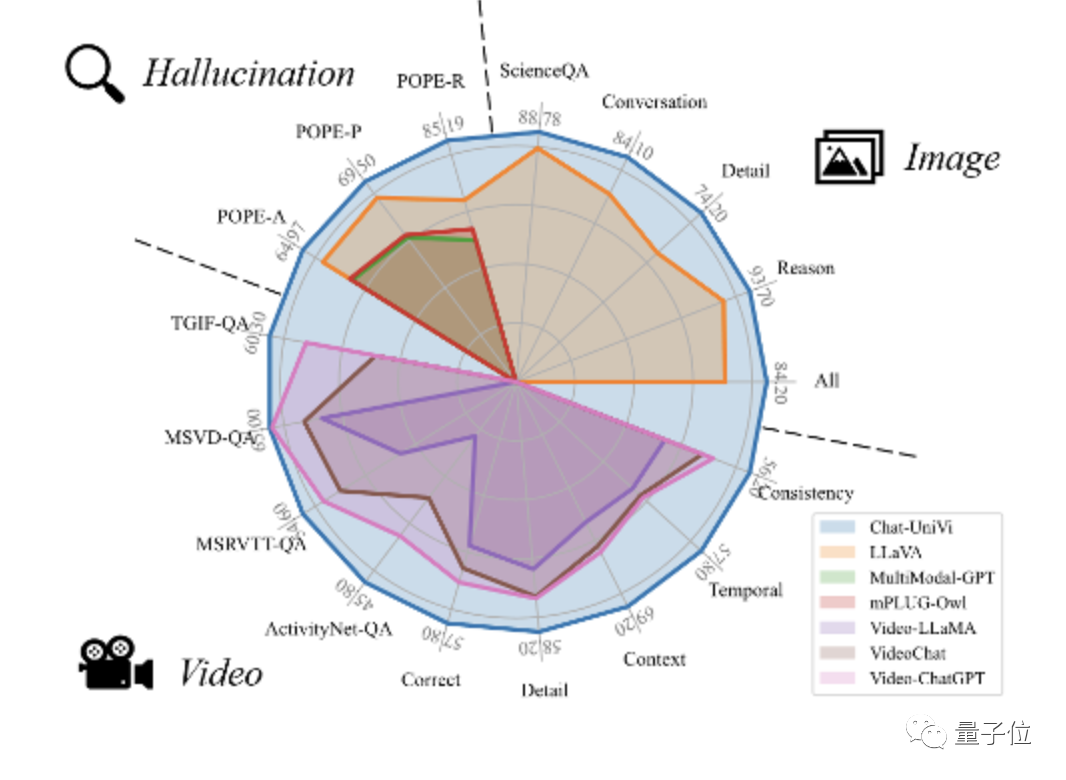
以此為基礎,Chat-UniVi在圖片及視頻上的17個基準上,都表現得還不錯。
現在,項目已經在GitHub和抱抱臉上開源。
更多關于新方法和Chat-UniVi的詳細信息,我們一起進一步來看看~
Chat-UniVi是什么?
了解基礎信息后,我們詳細地聊聊Chat-UniVi究竟是什么——
簡單來說,Chat-UniVi是一個統一的多模態大型語言模型,可以同時理解圖像和視頻。
目前VLM運用的方法,偏圖片理解的,往往使用大量視覺tokens來獲得更精細的空間分辨率。
偏視頻理解的方法,則常常選擇犧牲每幀的空間分辨率,以輸入更多幀來構建更精細的時間理解能力。
與它們不同,Chat-UniVi采用動態視覺token來統一表示圖像和視頻,動態token合并方法是無參數的,不需要額外訓練。
而動態token的來源,是漸進地聚類視覺token。
為了獲取這些動態的視覺token,研究人員基于最近鄰的密度峰聚類算法,逐步對視覺token進行分組和合并。
其中,圖片可以通過不同大小的視覺token進行建模。
舉個??:
圖中的羊就需要相對更多的視覺token進行細粒度表示;但背景里的雪山,一個視覺token就可以充分搞定建模。

至于視頻,處理視頻時,同樣采用最近鄰的密度峰聚類算法,以獲取事件的幀集合。
Chat-UniVi會把它劃分為多個關鍵事件,然后在事件內部拓展視覺token。
當然了,如果使用這種方法,更長的視頻就會被分配到更多的視覺token,因此如果身處可變長度視頻的情境下,這種方式比現有方式更有優勢。

總而言之,這種圖片和視頻的統一表示,一邊減少了視覺token的數量,一邊又保持了模型的表達能力。
同時又由于視覺token數量的減少,利用這種方式訓練模型和進行推理的成本,會大幅度降低——練一個具有130億參數的VLM,只需要3天。
多提一嘴,為了進一步提升模型性能,團隊還為LLM提供了一個多尺度表征。
多尺度表征的上層特征表示高級語義概念,而下層特征則強調了視覺細節的表示。
說到這,我們可以總結出Chat-UniVi的2大特點:
第一,因為獨特的建模方法,Chat-UniVi的訓練數據集可以是圖片與視頻的混合版,并且無需任何修改,就可以直接應用在圖片和視頻任務上。
第二,多尺度表征能幫助Chat-UniVi對圖片和視頻進行更到位、更全面的理解。
這也導致了Chat-UniVi的任務適應性更強,包括使用高層次特征進行語義理解,以及利用低層次特征生成詳細描述。

分兩階段訓練
Chat-UniVi的訓練分為兩個階段。
第一步是多模態預訓練。
在這個階段,研究人員凍結了LLM和視覺編碼器,同時只對投影矩陣進行訓練。
這種訓練策略使得模型能夠有效地捕獲視覺信息,而不會對LLM的性能造成任何明顯的損害。
第二步是聯合指令微調。
在第二階段,團隊對整個模型進行了全參數微調,使用了一個包含圖片和視頻的混合數據集。
通過在混合數據集上進行聯合訓練,Chat-UniVi實現了對大量指令的卓越理解,并生成了更自然、更可靠的輸出。
訓練過程中,團隊進行了如下實驗:
圖片理解實驗
Chat-UniVi在使用更少的視覺標記的同時,性能表現也很不錯。
7B參數的Chat-UniVi模型能達到13B大小LLaVA模型的性能水平。這證明了該方法的有效性。

視頻理解實驗
作為一個統一的VLM,Chat-UniVi超越了專門針對視頻設計的方法,如VideoChat和Video-ChatGPT。

圖片問答實驗
Chat-UniVi在ScienceQA數據集上性能表現良好,其性能優于專門針對科學問答進行優化的LLaMA-SciTune模型。

視頻問答實驗
在所有數據集上,Chat-UniVi均表現優于最先進的方法,如VideoChat和Video-ChatGPT等。

幻覺實驗
在幻覺評估方面,Chat-UniVi表現優于最近提出的最先進方法。
值得注意的是,作為一個7B模型,Chat-UniVi在性能上超越了13B參數大小的MiniGPT-4。
研究人員將這一成功歸功于多尺度表征,這使得模型能夠同時感知高級語義概念和低級視覺外觀。

人工評測實驗
同時,研究人員還進行了人工評估實驗。
他們發現,基于Flamingo的方法在理解視頻的能力上存在局限性。這種限制歸因于它們使用Q-Former從不同長度的視頻中提取固定數量的視覺標記,這阻礙了它們在建模時間理解方面的有效性。
相比之下,作為一個統一的模型,Chat-UniVi不僅優于基于Flamingo構建的方法,而且超越了專門為圖片和視頻設計的模型。

可視化
Chat-UniVi所采用的動態視覺token巧妙地概括了對象和背景。
這使得Chat-UniVi能夠以有限數量的視覺token,同時建模圖片理解所需的細粒度空間分辨率和視頻理解所需的細粒度時間分辨率。

團隊介紹
論文一作是北大信息工程學院博三學生金鵬。
通訊作者袁粒,北大信息工程學院助理教授、博士生導師。
其研究方向為多模態深度學習和AI4S,其中AI4S方向主要研究深度學習解決化學生物中的重大問題。
此前網絡大火的ChatExcel、ChatLaw等垂直領域大模型項目都出自袁粒團隊。
arXiv:https://arxiv.org/pdf/2311.08046.pdf
Demo:https://huggingface.co/spaces/Chat-UniVi/Chat-UniVi
GitHub:https://github.com/PKU-YuanGroup/Chat-UniVi
抱抱臉:https://huggingface.co/Chat-UniVi




























