













Omni-Scene:Gaussian統一表征下的自動駕駛多模態生成新SOTA!
寫在前面 & 筆者的個人理解
西湖大學和浙大的工作,利用3DGS的統一表征,結合擴散模型打通自動駕駛場景的多模態生成。近期生成+重建的算法越來越多,這說明單重建或者單生成可能都沒有辦法很好的cover閉環仿真,所以現在的工作嘗試兩者結合,這塊應該也是后面閉環仿真落地的方向。

先前采用基于像素的高斯表示的工作已經證明了前饋稀疏視圖重建的有效性。然而,這種表示需要交叉視圖重疊才能進行精確的深度估計,并且受到對象遮擋和截頭體截斷的挑戰。因此,這些方法需要以場景為中心的數據采集來保持交叉視圖重疊和完整的場景可見性,以規避遮擋和截斷,這限制了它們在以場景為核心的重建中的適用性。相比之下,在自動駕駛場景中,一種更實用的范式是以自車為中心的重建,其特征是最小的交叉視圖重疊和頻繁的遮擋和截斷。因此,基于像素的表示的局限性阻礙了先前工作在這項任務中的實用性。鑒于此,本文對不同的表示方法進行了深入分析,并引入了具有定制網絡設計的泛高斯表示方法,以補充其優點并減輕其缺點。實驗表明,在以自車為中心的重建中,Omni-Scene明顯優于最先進的像素Splat和MVSplat方法,并在以場景為中心的重構中取得了與先前工作相當的性能。此外Omni-Scene用擴散模型擴展了我們的方法,開創了3D駕駛場景的前饋多模態生成。
- 論文鏈接:https://arxiv.org/abs/2412.06273
總結來說,本文的主要貢獻有以下幾個方面:
- 我們提出了Omni Scene,這是一種全高斯表示,具有量身定制的網絡設計,用于自我中心重建,利用了基于像素和體積的表示,同時消除了它們的缺點。
- 將一種新的以自我為中心的重建任務引入到駕駛數據集(即nuScenes)中,目的是在僅給出單幀周圍圖像的情況下進行場景級3D重建和新穎的視圖合成。我們希望這能促進該領域的進一步研究。
- 實驗表明,我們的方法在自我中心任務上明顯優于最先進的前饋重建方法,包括pixelSplat和MVSplat。進一步還通過在RealEstate10K數據集上執行以場景為中心的任務的先前工作獲得了具有競爭力的性能。
- 通過將Omni Scene與2D擴散模型集成來展示其生成潛力,開創了一種以前饋方式多模態生成3D駕駛場景的新方法。

相關工作回顧
神經重建和渲染:最近利用神經渲染和重建技術的方法可以將場景建模為可學習的3D表示,并通過迭代反向傳播實現3D重建和新穎的視圖合成。NeRF因其在重建場景中捕捉高頻細節的能力而受到認可。然而,在渲染過程中,它需要對每條光線進行密集的查詢,盡管隨后進行了加速,但這仍然導致了高計算需求,限制了其實時能力。3D高斯散斑(3DGS)通過使用3D高斯顯式建模場景并采用高效的基于光柵化的渲染管道來緩解這個問題。盡管3DGS和NeRF及其變體在單場景重建中表現出了卓越的性能,但它們通常需要每個場景的優化和密集的場景捕獲,這使得重建過程耗時且不可擴展。與這些工作不同,我們的方法可以在單次前向過程中從稀疏觀測中重建3D場景。
隱式3D表示的前饋重建。這一系列工作將隱式3D先驗(如NeRF或光場)納入其網絡中,以實現前饋重建。基于NeRF的方法利用具有多視圖交叉注意力的Transformer,或使用極線和成本體積等投影3D先驗來估計重建的輻射場,這繼承了NeRF渲染的昂貴光線查詢過程。因此,這些方法在訓練和推理階段都非常耗時。相比之下,基于光場的方法可以通過基于光線到圖像的交叉注意力直接回歸每條光線的顏色來繞過NeRF渲染,這犧牲了可解釋性以提高效率。然而,由于缺乏可解釋的3D結構,它們無法重建場景的3D幾何形狀。
三維高斯前饋重建。最近使用3DGS的方法可以實現可解釋性和效率。通常,他們在網絡中采用類似于基于NeRF的方法(例如,極線、成本量和多視圖交叉注意力)的3D先驗,并采用基于像素的高斯表示來預測沿射線的每像素高斯分布以進行重建。然而,這種基于像素的表示依賴于大的交叉視圖重疊來預測深度,并且受到對象遮擋和截頭錐體截斷的影響,因此僅適用于以場景為中心的重建,適用性有限。相比之下,本文主要研究以自我為中心的重建,其特征是最小的交叉視圖重疊和頻繁出現的對象遮擋和截頭體截斷。這促使我們研究了一種新的3D表示方法,該方法不過度依賴于交叉視圖重疊,同時可以解決基于像素的表示的局限性。
Omni-Scene方法詳解
方法的整體框架圖如下所示:

Volume Builder
體積生成器旨在使用基于體積的高斯模型預測粗略的3D結構。主要的挑戰是如何將2D多視圖圖像特征提升到3D體積空間,而不顯式地保持密集的體素。我們使用Triplelane Transformer來解決這個問題。然后,提出了體積解碼器來預測體素錨定高斯GV。
Triplane Transformer。由于H×W×Z的立方復雜度,將體積表示為體素并為每個體素編碼特征是昂貴的。因此,我們采用三平面將體積分解為三個軸對齊的正交平面HW、ZH和WZ。一些對象級3D重建工作也采用三平面表示來壓縮體積。然而,它們要么依賴于三平面和圖像之間密集的每像素交叉注意力,要么要求輸入圖像也與三平面對齊,以進行直接的2D級特征編碼。它們都不適合具有更大體積和無約束數據收集的真實場景。
受最近3D感知方法]的啟發,我們的三平面變換器利用可變形的交叉注意力,在2D和3D空間之間實現稀疏但有效的空間相關性。這里我們以HW平面的特征編碼為例進行說明。如圖3(b)所示,我們定義了一組網格形狀的可學習嵌入作為transformer的平面查詢,其中C表示嵌入通道。然后,對于位于(h,w)處的查詢,我們將其擴展為沿Z軸均勻分布的多個3D柱點,并通過將它們投影回輸入視圖來計算它們在2D空間中的參考點Ref。由于這種透視投影的稀疏性,qh、w將只關注1/2輸入視圖中最相關的2D特征,以平衡效率和特征表現力。上述操作,即交叉圖像可變形注意,在圖3(b)中由紫色虛線箭頭表示。我們推導如下:

考慮到查詢柱點可能被遮擋或位于任何輸入視圖的截頭錐體范圍之外,我們進一步利用跨平面可變形注意力來豐富這些點的跨平面上下文。特別是,對于查詢,我們將其坐標(h,w)投影到HW、ZH和WZ平面上,以獲得三組參考點。

我們從不同的平面提取上下文信息,從而增強圖3(b)中紅色虛線箭頭所示的特征。推導如下:

對所有平面的查詢重復這兩種交叉注意力,我們可以獲得具有豐富語義和空間上下文的三平面特征,而不依賴于交叉視圖重疊,這對于之前僅依賴基于像素的高斯表示的方法來說是必要的。
Volume解碼器。然后,我們提出了體積解碼器來估計體素錨定高斯分布。具體來說,給定一個位于(h,w,z)的體素,我們首先將其坐標投影到三個平面上,通過雙線性插值獲得平面特征,然后進行平面求和,得出聚合的體素特征。
Pixel Decorator
Pixel Decorator由多視圖U-Net和像素解碼器組成,分別負責提取跨視圖相關特征和預測基于像素的高斯GP。由于GP是在與細粒度圖像空間對齊的情況下獲得的,因此它可以為粗體素錨定的高斯GV添加細節。此外,由于GP可以不投影到無限距離的位置,因此它可以用距離高斯來補充體積有界GV。
- 多視圖U-Net concat圖像特征;
- 像素解碼器對U-Net特征進行上采樣。
Volume-Pixel Collaboration
全高斯表示的核心在于基于體積和像素的高斯表示的協作。為此,我們提出了一種雙重方法,可以從兩個方面進行協作:基于投影的特征融合和深度引導的訓練分解。
基于投影的特征融合。我們的Volume Builder預計將在輸入視圖中遮擋或截斷的位置預測高斯分布,這超出了Pixel Decorator的設計目的。因此,為了使Volume Builder知道遮擋或截斷發生的位置,我們建議將三平面查詢與基于像素的高斯GP的投影特征融合。以HW平面為例,我們首先過濾掉GP中超出H×W×Z體積范圍的高斯分布。然后,我們收集GP剩余高斯人的U-Net特征,并將其投影到HW平面上。投影到相同查詢位置的特征被平均合并,并在線性層轉換后添加到QHW的相應查詢中。同樣的過程也適用于ZH和WZ平面。我們在實驗中證明,這種特征融合促進了GV和GP之間的互補相互作用,從而提高了性能。
Depth-Guided Training Decomposition:為了進一步加強協作,我們提出了一種深度引導訓練分解方法,根據基于像素和體積的高斯的不同空間屬性來分解我們的訓練目標。
整體損失函數如下:

實驗結果
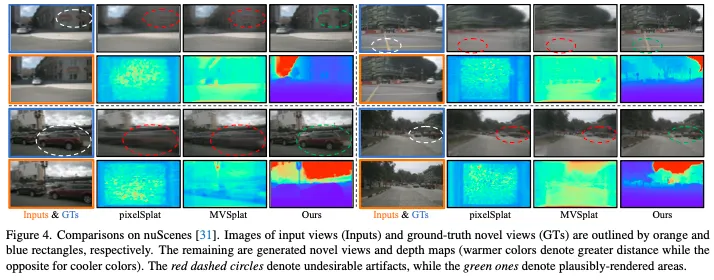
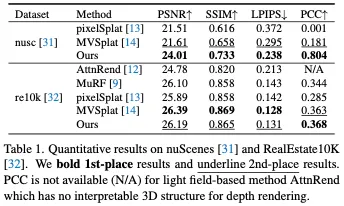

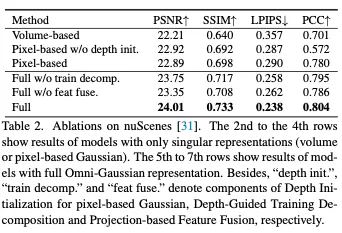

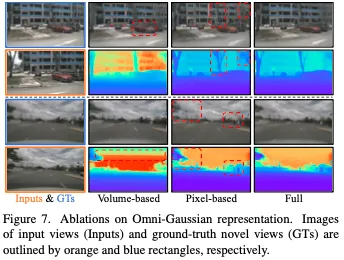
結論
本文提出了Omni-Scene,這是一種具有Omni高斯表示的方法,可以在基于像素和體積的高斯表示中達到最佳效果,用于自我中心稀疏視圖場景重建。采用鼓勵體像素協作的設計,我們僅從周圍的單幀觀測中實現了高保真場景重建。大量實驗表明,與以前的方法相比,我們在自我中心重建方面具有優勢。此外,我們將2D擴散模型集成到我們的框架中,這使得多模態3D場景生成具有多種應用。





























