華人團隊提出會創作的Paint Transformer,網友:這也要用神經網絡
神經網絡是個出色的繪畫家早已不是什么大新聞,它能把一副草圖變成風景畫,兩幅不同風格的畫之間進行風格遷移。

但這類工作都是端到端的,也就是說你并不知道神經網絡究竟是怎么畫出來這幅畫的。
神經繪畫(Neural Painting)應運而生,它指的是為給定的圖像生成一系列筆畫,并用神經網絡對其進行非照片式(non-photorealistically)再現的過程。
雖然基于強化學習的智能體可以為這個任務逐步生成一個筆畫序列,但是要訓練一個穩定的智能體卻不容易。
另一方面,筆劃優化方法需要在較大的搜索空間內迭代搜索一組筆劃參數,這種低效率的搜索很明顯會限制了基于強化學習方法的泛化性和實用性。
ICCV 2021上一篇文章提出,將該任務描述為一個集合預測問題,并提出了一種新的基于Transformer的框架,使用前饋網絡預測一組筆畫的參數,文中起名為Paint Transformer。
通過這種方式,文中提出的模型可以并行地生成一組筆畫,并近乎實時地獲得最終的大小為512 * 512的畫作。

教機器如何作畫并不是算是一個全新的研究課題,傳統方法通常設計啟發式繪畫策略,或者貪婪地選擇一個筆劃,一步一步地縮小與目標圖像的差異。

但近年來隨著神經網絡中RNN和強化學習的興起,傳統的方法的泛化性能就相形見絀了。
文中提出的模型將神經繪畫描述為一個漸進的筆劃預測過程。
在每一步,可以并行預測多個筆劃,以前饋方式最小化當前畫布和目標圖像之間的差異。
Paint Transformer由兩個模塊組成:筆劃預測器和筆劃渲染器。給定目標圖像和中間畫布圖像,筆劃預測器生成一組參數以確定當前筆劃集合。
然后,筆劃渲染器為Sr中的每個筆劃生成筆劃圖像,并將其繪制到畫布上,生成預測圖像。
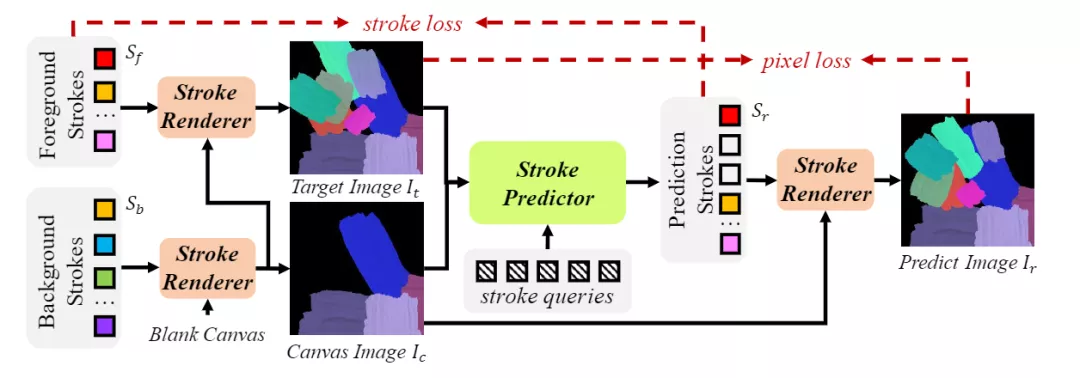
在Paint Transformer中,只有筆劃預測器(Stroker Predictor)包含可訓練的參數,而筆劃渲染器(Stroker Renderer)是一個無參數且可微分的模塊。
為了訓練筆劃預測器,又提出了一種利用隨機合成筆劃的新型自訓練Pipeline。在訓練期間的每次迭代中,首先隨機抽取前景筆劃集(foreground stroke set)和背景筆劃集。
然后,我們使用筆劃渲染器生成畫布圖像,將筆劃渲染器作為輸入,并通過將Sf渲染到Ic上生成目標圖像。
最后筆劃預測器可以預測筆劃集Sr,生成以Sr和Ic為輸入的預測圖像Ir。
需要注意的是,用于監督訓練的筆劃是隨機合成的,因此可以生成無限的訓練數據,而不依賴任何現成的數據集。
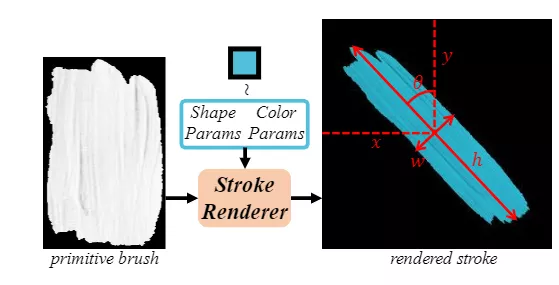
筆畫預測時主要考慮直線比劃,可以用形狀參數和顏色參數表示不同的直線。筆劃的形狀參數包括:中心點坐標x和y、高度h、寬度w和旋轉角度θ。筆劃的顏色參數包括RGB值表示為r、g和b。
自訓練pipeline的主要優點是,可以同時最小化圖像級和筆劃級的地面真實值和預測之間的差異。損失函數主要由三部分構成,像素損失、筆劃之間差異的測量以及筆劃損失。
1、像素損失(pixel loss),神經繪畫的直觀目標是重建目標圖像。因此,像素損失在圖像級別上懲罰不精確的預測。
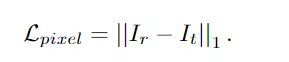
2、筆劃距離(stroke distance),在筆劃級別上,定義適當的度量標準以測量筆劃間的差異是很重要的。
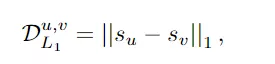
3、筆劃損失(stroke loss),在訓練期間,有效的真實筆劃的數量是不同的。根據DETR模型,采用產生最小筆劃水平匹配成本的筆劃排列來計算最終損失,利用匈牙利算法計算最佳二部匹配。
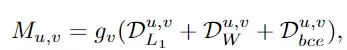
為了模仿人類畫家,在推理過程中,研究人員設計了一種從粗到精的算法來在推理過程中生成繪畫結果。給定一幅大小為H×W的真實圖像,Paint Transformer按從粗到細的順序在K尺度上運行。每種比例的繪畫都取決于前一比例的結果。
目標圖像和當前畫布將被切割成幾個不重疊的P×P塊,然后輸入到Stroke Predictor。
將文中的方法與兩種最先進的基于筆劃的繪制生成方法進行比較。與基于優化的方法(Optim)相比,Paint Transformer可以產生更吸引人和新穎的結果。

具體來說,在大的無紋理圖像區域中,我們的方法可以生成具有相對較少和較大筆劃的類人繪畫的效果。
在小的紋理豐富的圖像區域,Paint Transformer可以生成紋理更清晰的繪畫,以保持內容結構。
進一步使用更多筆劃實現Optim+MS,上述問題仍然存在。
與基于RL的方法相比,可以使用清晰的筆刷生成更生動的結果。同時,RL的結果有些模糊,缺乏藝術性,與原始圖像也太相似。
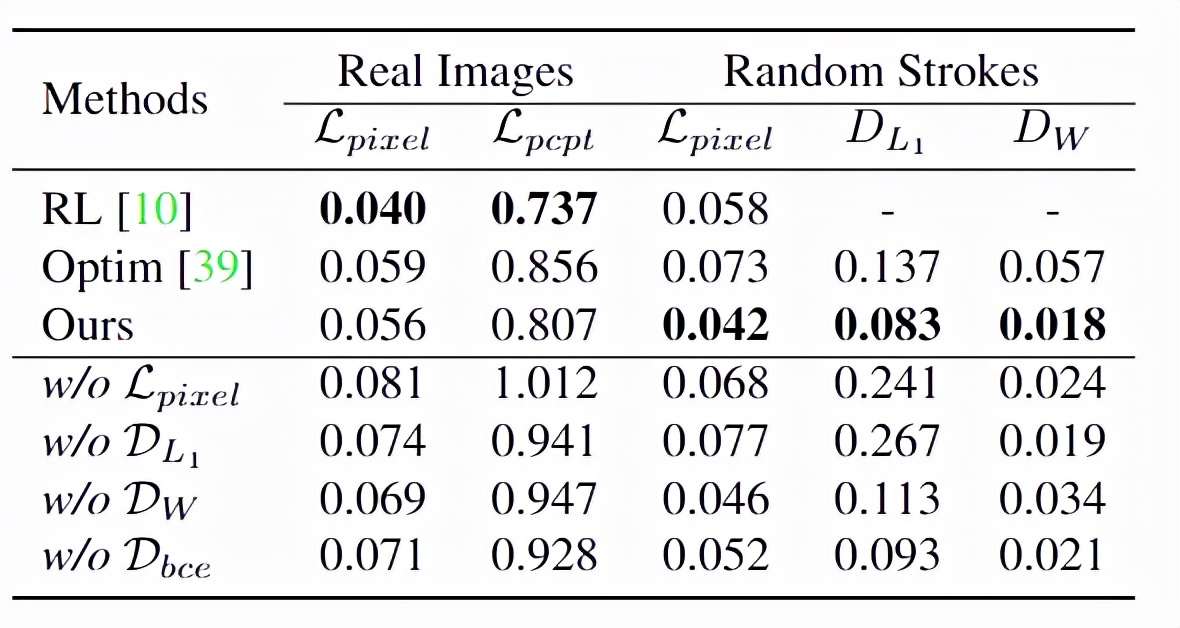
在量化比較上(Quantitative Comparison),由于神經繪畫的一個目標是重建原始圖像,直接使用像素損失和感知損失作為評估指標。
對于真實圖像,隨機選擇100幅風景畫,從WikiArt中隨機選擇100幅藝術畫,從FFHQ中隨機選擇100幅肖像畫進行評估。實驗結果與先前的定性分析一致:
(1)Paint Transformer具有生動的畫筆紋理,可以呈現的原始內容優于Optim
(2) 實現了最佳的內容保真度,但其內容清晰度較弱。
然后,為了比較筆劃預測性能,將合成的筆劃圖像輸入給Paint Transformer和Optim,并使用與Sec相同的度量來評估它們生成的筆劃。結果表明,該方法能夠成功地預測筆劃,并優于其他方法。
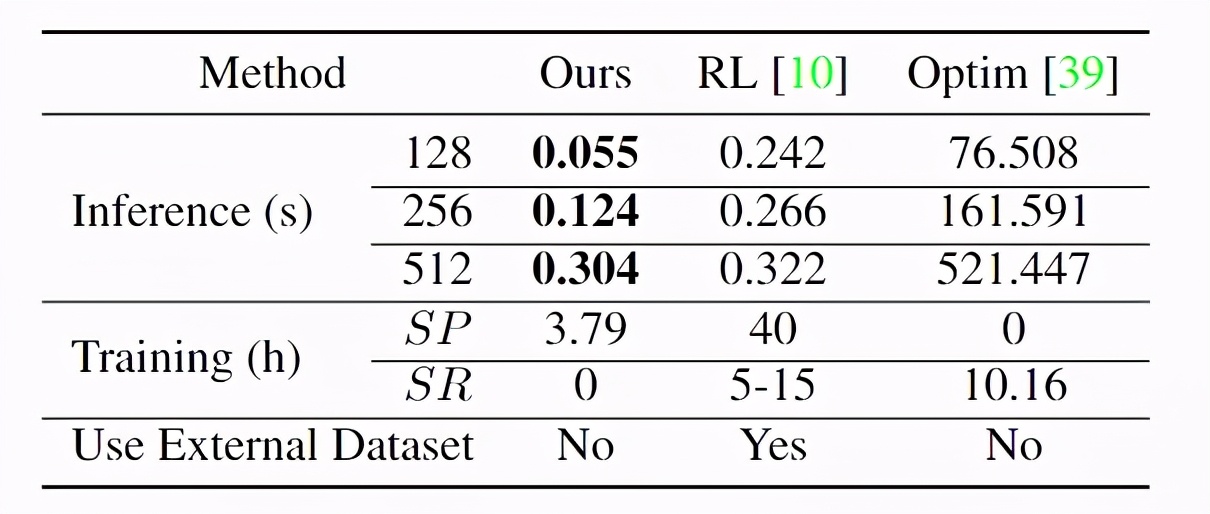
性能實驗結果表明,該方法具有較好的繪制性能,且訓練和推理成本較低。當使用單個Nvidia 2080Ti GPU測量訓練或推理時間,由于Paint Transformer以前饋方式平行產生一組筆劃,因此其運行速度明顯快于優化Optim基線,略快于基于RL的基線模型。
至于訓練過程,只需要幾個小時就可以訓練筆劃預測參數,從總訓練時間的角度來看。此外,無模型筆劃渲染器和無數據筆劃預測器效率高,使用方便。
目前代碼和模型都已經提交到GitHub上了。
文中另一個重要的貢獻是提供了一個數據集。由于沒有可用于訓練Paint Transformer的數據集,所以研究人員設計了一個自我訓練的pipeline,這樣它可以在沒有任何現成的數據集的情況下進行訓練,同時具有不錯的泛化能力。
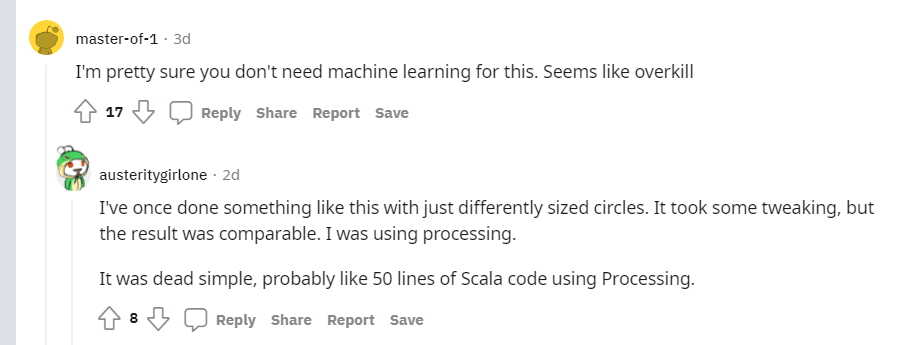
不過Reddit網友對此似乎有異議,認為這么簡單的任務根本不需要使用機器學習技術!
下面有網友回復說他之前也做過,只需要50行Scala代碼做的和這個就差不多了。
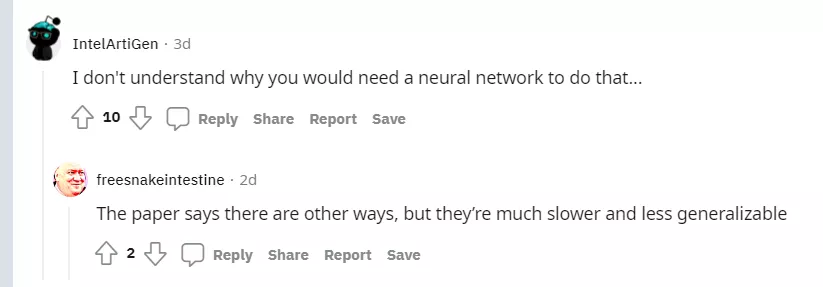
還有說不理解為什么要用神經網絡來做這個。
對此你怎么看?