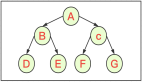
一文精通如何使用二叉樹
一、樹
一些基本概念有:
節點、父節點、子節點、兄弟節點、根節點、葉子節點;
高度(從葉子節點往上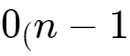 )、深度(從根節點往下0 ^ (n-1) )、層(從根節點往下1~n);n為層數;
)、深度(從根節點往下0 ^ (n-1) )、層(從根節點往下1~n);n為層數;
二、二叉樹
一些基本的概念:
- 左子節點、右子節點;二叉樹要求每個節點最多只能有兩個子節點,但并不要求必須有兩個子節點,單獨有左子節點或者右子節點都是可以的;
- 滿二叉樹,是指所有葉子節點都在最底層,除了葉子節點以外,每個節點都有左右兩個子節點;
- 完全二叉樹,是指所有葉子節點都在最底下兩層,最后一層的葉子節點是從左到右依次排列的,中間不能有空缺,其它層節點個數都要達到最大,不能有空缺;
- 存儲方法有鏈式存儲法、順序存儲法;
大部分二叉樹都可以使用如下鏈式存儲法來進行表示,必然要左右節點空間來指向各自的左子節點和右子節點;
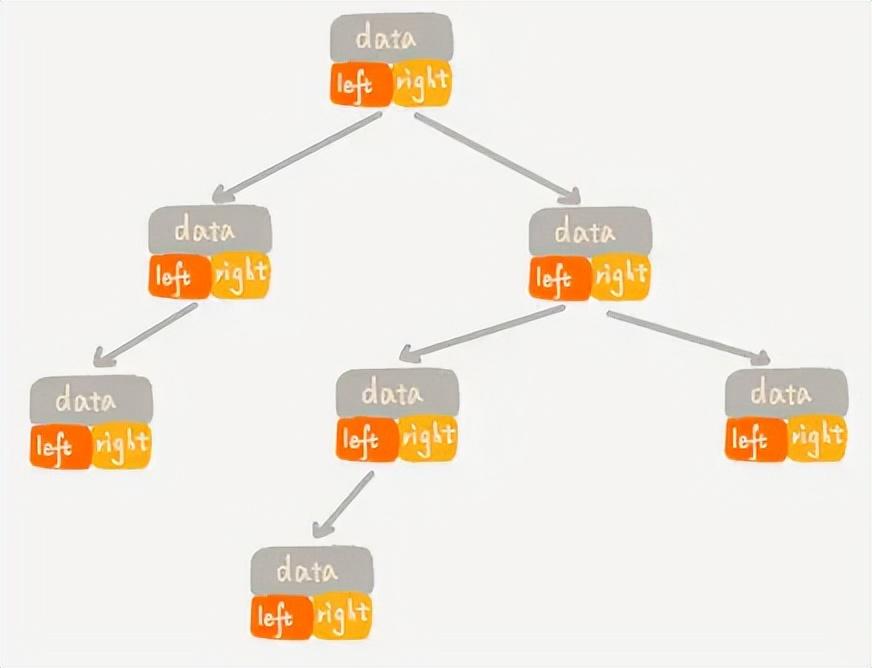
二叉樹的鏈式存儲
順序存儲法則是利用一個數組,將當前節點存放在下標為i的地址中,那么左子節點就存放在2i的地址中,右子節點存放在2i+1的地址中;反過來,已知某個節點位置為k,那么它的父節點位置就是k/2;但是當二叉樹不是一顆完全二叉樹的時候,就會比較浪費數組存儲空間;因此,當二叉樹為完全二叉樹的時候,采用順序存儲是最優的;
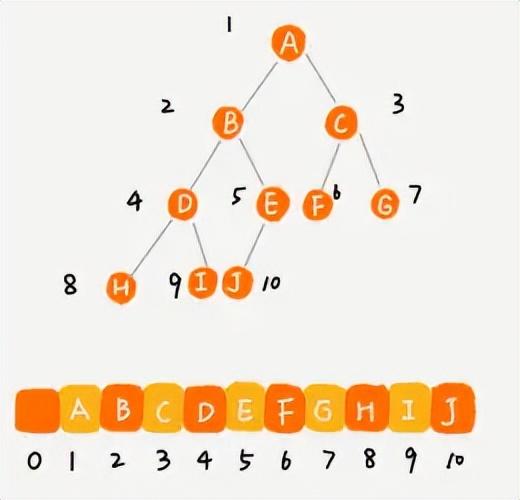
完全二叉樹的順序存儲
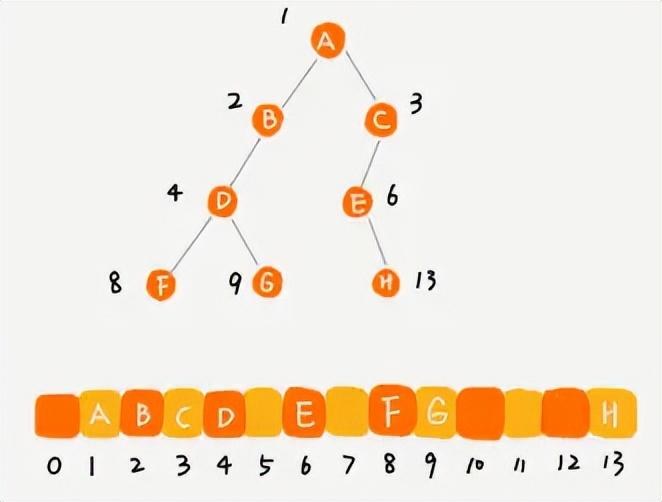
非完全二叉樹的順序存儲
- 遍歷分為前序遍歷、中序遍歷和后序遍歷;
前序遍歷,先自己,再左邊,最后右邊;
中序遍歷,先左邊,再自己,最后右邊;
后續遍歷,先左邊,再右邊,最后自己;
三、二叉查找樹
在二叉樹的基礎上,滿足如下條件:對于任意一個節點,其左子樹上的每個節點值都要小于當前節點的值,其右子樹上的每個節點值都要大于當前節點的值;
查找,目標元素target和當前節點比較,如果比當前節點小那么就在左子樹中繼續查找,反之則在右子樹中查找;
插入,目標元素target和當前節點比較,如果比當前節點小并且當前節點沒有左子樹,那么作為左子節點插入,如果有左子樹,那么繼續往左遍歷;如果比當前節點大并且當前節點沒有右子樹,那么作為右子節點插入,如果有右子樹,那么繼續往右遍歷;
刪除,先找到目標元素,如果目標沒有子節點,直接將其刪除即可;如果目標有子節點(左右子節點都可),那么將目標節點的父節點指向目標節點的子節點即可;如果目標節點同時擁有左右子樹,那么就需要在右子樹中找到最小值替換當前節點;(如果想要提高刪除的性能,我們還是可以采用標記刪除法,以空間換時間)
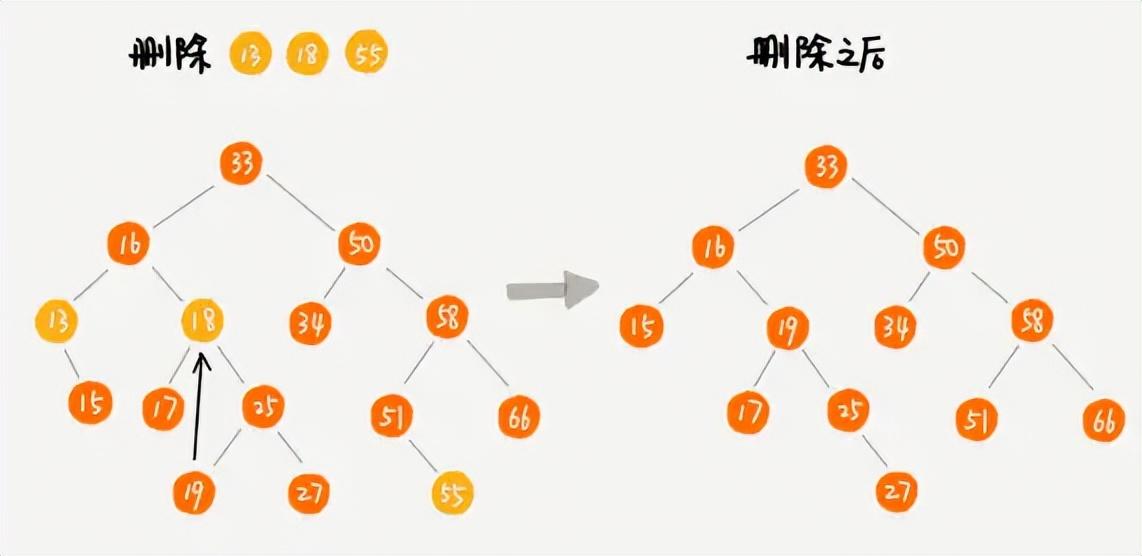
二叉查找樹的刪除操作
- 查找最大值和最小值;
- 尋找給定元素的前驅和后繼節點;
- 中序遍歷輸出完全有序的數列,時間復雜度O(n),相較于原先講過的八大排序算法來說,算是最好的排序算法了;
- 重復數據的存儲;
相同值存放在同一個節點;
相同值存放在右子樹;但是要求在查找和刪除的時候,一定要遍歷到葉子節點才能找到所有相同的元素;
- 時間復雜度分析,在最壞的情況下,二叉查找樹退化為鏈表,那么所有操作的時間復雜度都是O(n),但是在完全二叉樹時,時間復雜度取決于樹的高度,就是O(logn);
四、平衡二叉查找樹
如何讓二叉查找樹盡量保持平衡,讓時間復雜度維持在O(logn),這是平衡二叉查找樹需要做的事情。那什么樣子的二叉查找樹可以被稱為平衡的二叉查找樹呢?
嚴格的定義就是:任意一個節點的左右子樹的高度相差不能大于1;比如AVL樹,這就是一種高度平衡的,完全符合平衡二叉樹定義的。
但是,比較嚴格的平衡二叉樹實現起來有些復雜,需要耗費過多的資源在平衡高度差不超過1這個條件上面,反而矯枉過正了。因此,我們只要能設計出一種二叉查找樹,使得所有節點的左右子樹看起來相對均衡,那么也可以將它稱為符合要求的平衡二叉查找樹,比如下面的紅黑樹。
五、紅黑樹
紅黑樹是一種不嚴格的平衡二叉查找樹,它具有以下要求:
- 根節點是黑色的;
- 每個葉子節點都是黑色的空節點,不存儲數據;
- 任何上下相鄰的節點都不能同時為紅色,紅色節點是被黑色節點隔開的;
- 每個節點到到其所有葉子節點的路徑都包含相同數目的黑色節點;
- 插入的節點必須是紅色的,新插入的節點都是放在葉子節點上的;
紅黑樹在插入節點時,如果父節點是黑色的,那么直接插入就行;如果插入的節點是根節點,那么將它改為黑色即可;除此之外的任何情況,都會破壞如上紅黑樹的要求,此時就需要通過左旋、右旋或者改變顏色才能重新符合紅黑樹的要求。紅黑樹的實現過程和平衡過程都比較復雜,一般了解即可。
紅黑樹具有穩定的性能,在插入、刪除和查找時都能穩定在O(logn),同時不會浪費太多資源進行平衡的操作,所以在工業運用上,比嚴格的平衡二叉查找樹要更加地受歡迎。
六、遞歸樹
遞歸樹主要可以用來分析復雜算法的時間復雜度;比如原先說過的歸并排序,時間復雜度是O(logn),這個使用遞歸樹怎么分析呢?
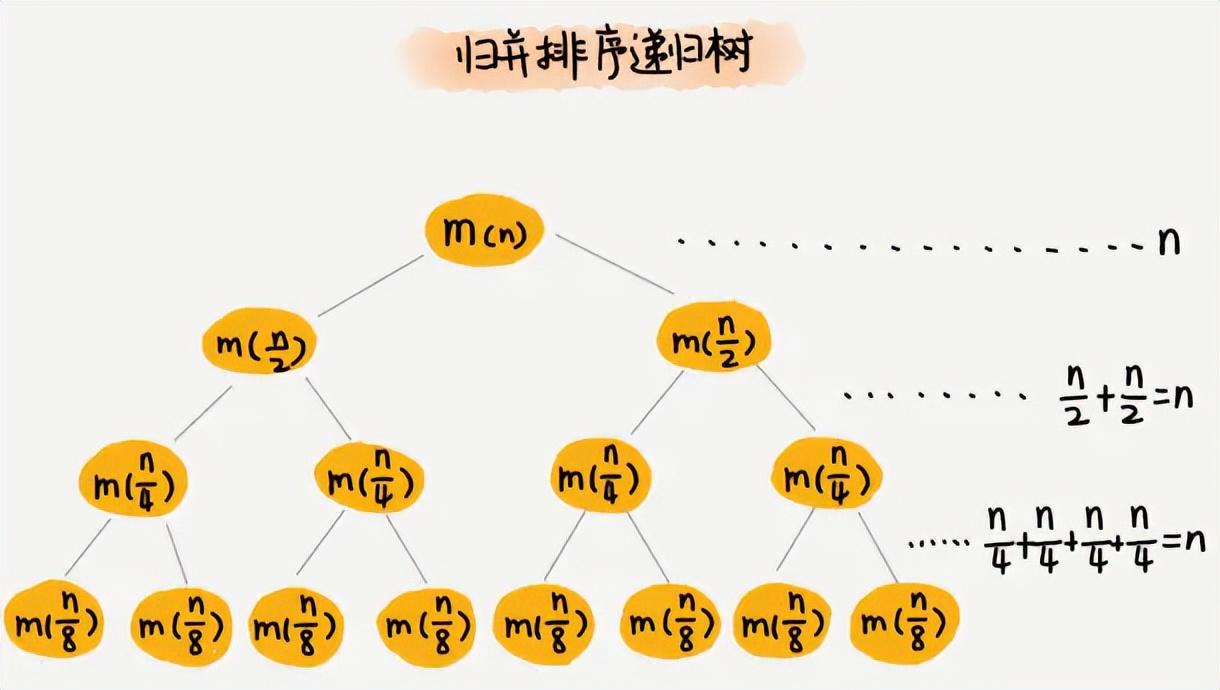
歸并排序的遞歸樹
歸并排序的過程就是每次分解都是1/2,直至每個節點只有一個元素為止,然后從下往上進行相鄰節點的歸并排序,直至歸并為一個數列。
分解的過程時間耗費比較小,因為可以利用數組隨機訪問的特性一分為二,所以時間可以記為常數C;
歸并的時候每層都需要比較n個元素,所以時間復雜度為O(n),假設樹的高度為h,那么時間復雜度就是O(hn),其中高度怎么計算呢?在滿二叉樹的時候,樹的高度可以表示為logn,所以歸并過程的時間復雜度就近似為O(nlogn),那么整個分解和歸并的時間復雜度就是O(C+nlogn),去掉低階,最終得到歸并排序的時間復雜度就是O(logn)。
七、總結
二叉樹比散列表的優勢在哪里?
散列表中的數據是無序存儲的,如果我們需要有序的數列,就必須先排序,時間復雜度取決于你用的排序算法以及無序數據的排列情況,但是肯定不會好于O(n),但是二叉查找樹,又稱二叉排序樹天然就是有序的,只要按照中序遍歷輸出即可,時間復雜度穩定為O(n);
散列表有擴容操作,哈希計算操作,還會有沖突再散列的問題,其時間效率并不穩定;而平衡二叉樹能讓查找、插入和刪除的時間復雜度能穩定在O(logn);當數據量大的時候,平衡二叉樹的優勢和性能將會遠超散列表;
散列表實現起來比較復雜,需要考慮散列函數的設計、裝載因子的設計、擴容和縮容方案、沖突再散列如何解決等;而平衡二叉樹只需要考慮平衡的問題,比較簡單,方案也比較成熟。